

개발을 하다 보면 아스키 코드, 유니코드란 말 참 많이들어 보셨을겁니다.
많이는 들어봤지만 자바스크립트를 공부할때는 실제로 크게 쓰이지않아 나중에 알아봐야지 했지만,
자바를 공부하고 나서 아스키코드와 유니코드를 이해하는게 필요하다고 느끼게 되어
ASCII(아스키 코드)와 Unicode(유니코드)가 무엇인지에 대해 포스팅해보려 합니다.
설명하기 앞서 인코딩(encoding)과 디코딩(decoding)에 대해 알아보겠습니다.
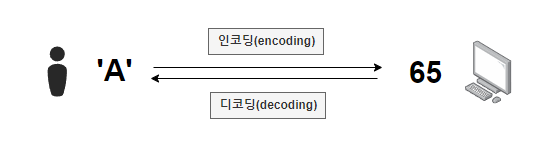
위 그림을 보면 문자 'A'의 유니코드가 65인 것을 알 수 있습니다.
그래서 문자 'A'를 인코딩하면 65가 되고, 반대로 65 유니코드를 디코딩하면 문자 'A'가 됩니다.
여기서 인코딩이란 ? 문자를 코드로 변환하는 것을 말합니다.
즉, 컴퓨터는 0과 1밖에 모르기 때문에 'A'라는 문자를 알지 못해 컴퓨터가 이해할 수 있는 코드 65 ( 1000001 ) 로 변환해 주는 것입니다. (이진법 : 1000001)
디코딩이란 ? 인코딩의 반대로 코드 65를 문자'A'로 해석해서 우리가 알 수 있는 언어로 변환해 주는 것입니다.
만약, 인코딩에 사용된 코드표와 디코딩에 사용된 코드표가 서로 다르면 이상한 글자들로 바뀌어 알아볼수 없게 됩니다.
자 이제 ASCII(아스키 코드)와 Unicode(유니코드)에 대해 알아봅시다.
ASCII(아스키 코드)

ASCII 란 'American Standard Code for Information Interchange'의 약자로 정보교환을 위한 미국 표준 코드라는 뜻입니다.
ASCII는 128개 ( 2^7 ) 의 문자 집합을 제공하는 7bit 부호로, 처음 32개의 문자는 인쇄와 전송 제어용으로 사용되는 '제어문자'로 제어 문자들은 역사적인 이유로 남아 있으며 대부분은 더 이상 사용되지 않습니다.
마지막 문자(DEL)를 제외한 33번째 이후의 문자들을 출력할 수 있는 문자들로, 기호와 숫자, 영대소문자로 이루어져있습니다.
여기서 왜 8 bit가 아닌 7 bit를 사용하냐 의문이 들 수 잇는데, 나머지 1 bit는 패리티비트(parity bit)로 데이터 에러의 탐지를 위해 사용합니다.
패리티비트(parity bit)
데이터의 전달 과정에서 오류가 생겼는지 검사하기 위해 일곱자리의 이진수에서 1이 홀수개라면 끝에 1을 붙이고, 짝수개라면 끝에 0을 붙입니다.
ASCII는 숫자 '0~9' , 'A~Z', 'a~z' 가 연속적으로 배치되어 있다는 특징이 있으며, 이러한 특징은 프로그래밍에서 유용하게 활용됩니다.

확장 ASCII ( 8 bit로 주로 라틴어에 사용 )
일반적으로 데이터는 byte단위로 다뤄지는데 ASCII 코드는 7 bit로 1 bit가 남습니다.
이 남는 공간을 활용해 문자를 추가로 정의한 것이 확장 ASCII 입니다.
확장 아스키에 추가된 128개의 문자는 여러 국가와 기업에서 서로의 필요에 따라 다르게 정의해서 사용합니다.
ISO(국제 표준화 기구)에서 확장 아스키의 표준을 몇 가지 발표 했는데, 그 중 대표적인 것이 'ISO 8859-1' 입니다.
이 확장 아스키 버전은 'ISO Latin 1'이라고도 하며 서유럽에서 일반적으로 사용하는 문자들을 포함합니다.
코드 페이지 (cp)
IBM이 자사의 PC에 확장 ASCII를 도입해 사용하기 시작할 때, 확장 ASCII 코드는 여러 국가와 기업에서 서로의 필요에 따라 다르게 정의하기 때문에
PC를 사용하는 지역이나 국가에 따라 여러 버전의 확장 ASCII가 필요했습니다.
IBM은 이를 '코드 페이지(cp)'라 하고, 각 코드 페이지에 'CP xxx'와 같은 형식으로 이름을 붙였습니다.
한글 윈도우는 'CP 949'를, 영문 윈도우는 'CP 437'을 사용합니다.
Unicode(유니코드)

옛날 같은 경우 같은 지역 안에서만 문서교환이 주로 이뤄졌지만, 인터넷이 발달 되면서 서로 다른 지역의 다른 언어를 사용하는 컴퓨터간의 문서교환이 활발해지기 시작했습니다.
그러자 서로 다른 문자 인코딩을 사용하는 컴퓨터간의 문서교환에 어려움을 겪게 되었는데,
이러한 어려움을 해결하고자 전 세계의 모든 문자를 하나로 통일된 문자집합으로 표현하고자 'Unicode'를 만들었습니다.
7 bit를 사용하여 128가지를 표현할 수 있는 ASCII와 달리 Unicode는 2 byte, 즉 16 bit를 사용해 2^16가지 (65,536)를 표현할 수 있습니다.
하지만 모든 문자를 표현하기에는 역부족이여서 21 bit (약 200만 문자)로 확장하여 새로 추가된 문자들을 보충 문자라고 합니다.
이 보충 문자를 표현하기 위해서는 char 타입이 아닌 int 타입을 사용해야 하는데, 보충문자는 거의 쓸 일이 없으므로 다음에 필요시 자세히 알아보도록하겠습니다.
유니코드는 유니코드에 포함시키고자 하는 문자들의 집합을 정의하였는데, 이것을 유니코드 문자 셋 또는 캐릭터 셋 (character set)이라고 합니다.
그리고 이 캐릭터 셋에 번호를 붙인 것이 바로 유니코드 인코딩 입니다. ( UTF-8, UTF-16, UTF-32 )
UTF-8(8-bit Unicode Transformation Format)
문자열 집합과 인코딩 형태를 8비트 단위로 한다는 의미를 가집니다.
유니코드 한 문자를 나타내기 위해서 1바이트에서 4바이트까지를 사용하는데 이를 가변 길이 인코딩 방식이라고 합니다.
ASCII문자들은 7비트로 표현이 가능하여 1바이트로 하나의 문자를 표현이 가능한데
ASCII를 주로 사용하는 시스템에서 모든 문자를 4바이트로 사용한다면 이것은 지나친 저장소의 낭비가 될 수 있습니다.
그래서 ASCII 코드로 표현가능한 것들은 1바이트로 표현하고 그것이 안된다면 2바이트 이상을 사용하는 방식입니다.
- 어떻게 가변길이로 문자를 표현하는가 ?
첫번째 바이트가 시작되는 비트가 무엇이냐에 따라서 뒤의 몇바이트까지 읽어낼 것인가를 결정하게 됩니다.
0xxxxxxx 첫번째 바이트가 0으로 시작한다면 0 이외의 7비트를 ASCII로 인식합니다.
110xxxxx 10xxxxxx 두번째 바이트까지 읽어서 하나의 문자로 표현 ( 최상위 비트의 맨 앞이 110으로 0까지 1이 2개 이므로 2 byte )
1110xxxx 10xxxxxx 10xxxxxx 세번째 바이트까지 읽어서 하나의 문자로 표현 ( 최상위 비트의 맨 앞이 1110으로 0까지 1이 3개 이므로 3 byte )
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx 네번째 바이트까지 읽어서 하나의 문자로 표현 ( 최상위 비트의 맨 앞이 11110 0까지 1이 4개 이므로 4 byte )
여기서 UTF-8의 강점은 ASCII방식과 완벽하게 호환된다는 것입니다.
첫자리를 0으로 채우고 나머지 7비트를 통하여 ASCII와 일대일로 대응하도록 표현이 가능합니다.
2바이트 이상일 때는 첫 바이트의 최상위비트부터 0인 비트까지의 1인 비트의 수가 바이트의 수를 나타냅니다.
그리고 첫 바이트다음에 나오는 바이트는 10으로 시작하는 원칙을 따릅니다. ( 한 문자를 표현하는 바이트들이 다른 문자의 것으로 혼동되는 것을 막기위한 방법 )
UTF-8은 최근에 표준으로 가장 많이 사용되고 있는 인코딩 방식으로 웹문서 인코딩 방식으로 많이 사용됩니다.
UTF-16(16-bit Unicode Transformation Format)
UTF-16은 16비트(2바이트)단위로 인코딩 됩니다.
2바이트 단위로 인코딩하여 고정 길이 인코딩 방식 입니다.
기본 다국어 평면의 문자들은 16비트가 그대로 문자로 인코딩 될 수 있으며, 그 이외의 문자는 특별히 정해진 방식으로 32비트로 인코딩 됩니다.
따라서 2바이트 또는 4바이트로 문자가 인코딩됩니다.
여기서 의문이 들 수 있습니다. '고정 길이 인코딩 방식'이면서 16비트와 32비트로 크기가 변경되는가 ?
왜냐하면 '고정길이'라는 것은 특정한 데이터가 어떠한 기준이되는 크기의 블록에 들어가서 그 단위로 처리된다는 것으로,
UTF-16같은 경우는 2바이트, 4바이트의 크기의 블록에 유니코드를 적재하여 인코딩하는 방식이라는 것입니다. 따라서 데이터가 만약 그 블록보다 작다면 빈 공간이 존재하게 됩니다.
'가변길이'라는 것은 데이터의 크기에 알맞게 그 블록의 크기가 조정되는 것으로 이해할 수 있습니다.
모든 문자의 크기가 동일한 UTF-16이 문자를 다루기는 편하지만, 1 byte로 표현할 수 있는 영어와 숫자가 2 byte로 표현되므로
대부분의 컴퓨터 환경들은 영어로 구축되어 있기에 영어를 1바이트로 표현할 수 있는 UTF-8이 거의 표준처럼 사용되고 있는 추세입니다.
UTF-16이 UTF-8에 비해 ASCII와의 호환성이 떨어지는 문제가 있지만, UTF-16은 한글을 2바이트로 표현이 가능합니다.
따라서 UTF-8이 한글을 3바이트로 표현하는 것으로 보아, 한글로 된 문서들을 표현하기에는 UTF-16이 데이터의 크기에서 이점을 가져갈 수 있는 인코딩 방식입니다.
Java언어에서는 이 인코딩 방식을 표준으로 사용합니다. 그래서 char형 변수는 하나에 2바이트로 잡혀서 사용하는 것입니다.
참고자료
https://hyoje420.tistory.com/3