

ELK 도입 이유
ELK가 무엇인지에 대해 알아보고 싶다면 아래 포스팅을 참고.
[ELK] ElasticSearch란? ELK란? 내부 구조, 장단점, RDB와 차이
ElasticSearch란? Elasticsearch는 Apache Lucene기반의 Java 오픈 소스 분산 검색 엔진이다. Elasticsearch를 통해 방대한 양의 데이터를 신속하게(거의 실시간) 저장, 검색, 분석을 수행할 수 있다. Elasticsearch는
hstory0208.tistory.com
ELK를 적용한 이유
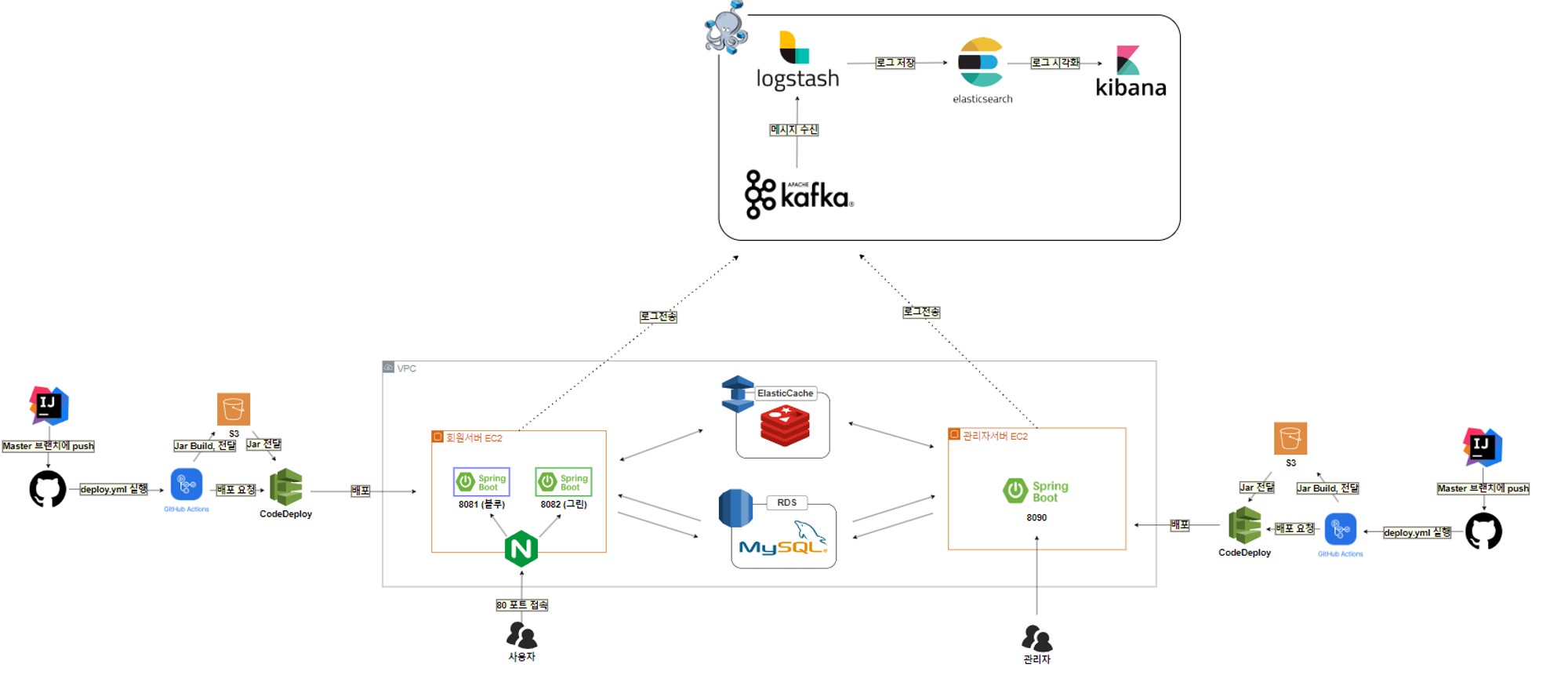
필자의 쇼핑몰 서비스는 아래 처럼 사용자 서버와 관리자 서버가 분리되어 있다.
이렇게 분리된 서버를 관리하기 위해서 ELK를 적용하기전에는 어디서 어느 시점에 장애가 발생했는지 확인하려면 실행되는 서비스의 로그를 서버별로 확인해야 했다.
하지만 이렇게 서버별로 로그를 확인하는 것은 상당히 비효율적이고
MSA가 적용되어 각 기능 별로 서버가 분리되어 서버들이 무수히 많아진다면 서버별로 로그를 확인해 장애에 대응하는 것은 거의 불가능에 가까울 것이다..
이러한 유지 보수 비용을 줄이기 위해, 로그를 한 곳에 모아 시각화하여 분석하고자 ELK를 도입하게 되었다.
ELK + Kafka를 함께 사용한 이유
기존에 관리자 서버에서 관리자가 회원의 리뷰에 답글을 달았을 때 해당 이벤트를 실시간으로 전달해 실시간 알림을 표시하기 위해 Kafka를 추가했었다.
이런 작은 서비스에는 트래픽이 작기 때문에 문제가 발생하진 않겠지만
큰 서비스의 상황을 경험하고자 과도한 트래픽이 몰렸을 경우에 ELK 스택의 문제로 인해 로그가 손실되는 일이 없도록 가용성을 위해 기존에 추가한 Kafka를 ELK 앞단에 추가하였다.
Kafka에 대해 알아보고 싶다면 아래 포스팅 참고.
[Kafka] 카프카란 ? 주요개념 정리 및 Pub/Sub 모델 비교
카프카(kafka) 란? Kafka는 대규모 실시간 데이터 스트리밍을 처리하는 데 사용되는 분산 이벤트 스트리밍 플랫폼이다. 먼저 "분산 이벤트 스트리밍"이라는 용어에 대해 알아보자 분산 이벤트이라
hstory0208.tistory.com
ELK + Kafka 추가하기
1️⃣ 아래의 git 레포지토리를 clone 하여 ELK 설정 폴더를 다운로드 받는다.
git clone https://github.com/900gle/docker-elk
2️⃣ 해당 레포지토리의 메인 경로인 docker-elk에서 docker-compose.yml 파일에 아래 zookeeper와 kafka 서비스를 다음과 같이 추가.
version: '3.7'
services:
...
kibana:
build:
context: kibana/
args:
ELASTIC_VERSION: ${ELASTIC_VERSION}
volumes:
- ./kibana/config/kibana.yml:/usr/share/kibana/config/kibana.yml:ro,Z
ports:
- 5601:5601
environment:
KIBANA_SYSTEM_PASSWORD: ${KIBANA_SYSTEM_PASSWORD:-}
networks:
- elk
depends_on:
- elasticsearch
restart: unless-stopped
zookeeper:
container_name: zookeeper
image: confluentinc/cp-zookeeper:latest
ports:
- "9900:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
networks:
- elk
kafka:
container_name: kafka
image: confluentinc/cp-kafka:latest
depends_on:
- zookeeper
ports:
- "9092:9092"
environment:
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:29092,PLAINTEXT_HOST://localhost:9092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_CREATE_TOPICS: "ek-log:1:1"
volumes:
- /var/run/docker.sock:/var/run/docker.sock
networks:
- elk
networks:
elk:
driver: bridge
volumes:
elasticsearch:위 docker compose 파일을 보면 서비스들이 elk라는 이름의 네트워크로 설정되어 있는 것을 볼수 있다.
이렇게 네트워크를 설정한 이유는 서비스 간 통신을 가능하게 하기 위해서이다.
Docker 컨테이너는 기본적으로 격리된 환경으로 실행되기 때문에 컨테이너 간 통신을 하기 위해서는 위처럼 네트워크를 명시적으로 설정해주어야 통신이 가능하다.
또한 같은 도커 네트워크에 속해 있는 경우에는, 컨테이너간의 서비스 이름을 사용해 DNS 조회가 가능하다.
즉, 카프카 서비스에 접근할 경우 IP 주소 대신 서비스 이름인 "kafka"를 사용해 다른 컨테이너에 접근할 수 있는 것이다.
추가로 Kafka 서비스의 설정에서 KAFKA_ADVERTISED_LISTENERS 옵션에 2개의 주소가 포함되어 있다.
이 옵션은 클라이언트가 브로커에 연결하기 위해 사용하는 호스트 이름과 포트를 지정하는 것으로 각각의 주소는 다음과 같은 역할을한다.
📌 PLAINTEXT://kafka:29092
Docker 네트워크 내에서 다른 서비스(예: Logstash)가 Kafka에 접근할 때 사용. (kafka는 Docker Compose에서 정의한 서비스 이름)
📌 PLAINTEXT_HOST://localhost:9092
Docker 외부에서 Kafka에 접근할 때 사용. 여기서 localhost는 Docker 호스트를 가리킨다.
즉, 컨테이너 내부에서는 kafka:29092를 통해 Kafka에 접근하고, 컨테이너 외부(즉, Docker 호스트 또는 애플리케이션)에서는 localhost:9092를 통해 Kafka에 접근하는 것이다.
3️⃣ .env 파일 설정 변경
ELASTIC_VERSION=8.10.2
## Passwords for stack users
#
# User 'elastic' (built-in)
#
# Superuser role, full access to cluster management and data indices.
# https://www.elastic.co/guide/en/elasticsearch/reference/current/built-in-users.html
ELASTIC_PASSWORD='비밀번호'
# User 'logstash_internal' (custom)
#
# The user Logstash uses to connect and send data to Elasticsearch.
# https://www.elastic.co/guide/en/logstash/current/ls-security.html
LOGSTASH_INTERNAL_PASSWORD='비밀번호'
# User 'kibana_system' (built-in)
#
# The user Kibana uses to connect and communicate with Elasticsearch.
# https://www.elastic.co/guide/en/elasticsearch/reference/current/built-in-users.html
KIBANA_SYSTEM_PASSWORD='비밀번호'먼저 ELASTIC_VERSION 을 다음과 같이 8.10.2 맞춰 주어야 한다. (버전이 달라질 경우 로그를 통해 확인해서 맞춰주면 된다.)
필자의 경우에는 변경하지 않았을 때 8.8.1 로 실행되면서 다운그레이드 불가능하다는 에러가 나와 로그에 나와있는 8.10.2 버전으로 수정해주었다.
그 다음으로 우리가 사용할 위 3개의 서비스의 비밀번호를 작성하자.
참고로 비밀번호는 5글자 이상이어야 한다.
5글자보다 작다면 실행시에 각 서비스마다 에러로그가 발생하면서 작동하지 않을 것이다.
4️⃣ elasticsearch.yml 수정
---
## Default Elasticsearch configuration from Elasticsearch base image.
## https://github.com/elastic/elasticsearch/blob/main/distribution/docker/src/docker/config/elasticsearch.yml
#
cluster.name: docker-cluster
network.host: 0.0.0.0
## X-Pack settings
## see https://www.elastic.co/guide/en/elasticsearch/reference/current/security-settings.html
#
xpack.license.self_generated.type: basic
xpack.security.enabled: true
기본은 xpack.license.self_generated.type 값이 trial로 되어 있을 것이다.
trial은 30일 무료 체험판이라고 하니 나는 basic으로 변경했다.
5️⃣ logstash.conf 수정
input {
kafka {
bootstrap_servers => "kafka:29092"
topics => ["토픽이름"]
consumer_threads => 1 #각 토픽에 대해 생성할 컨슈머 스레드의 수 (기본 값 : 1) 1 = 순서 보장
decorate_events => true
}
}
## Add your filters / logstash plugins configuration here
output {
elasticsearch {
hosts => "elasticsearch:9200"
user => "logstash_internal"
password => "${LOGSTASH_INTERNAL_PASSWORD}"
index => "ek-log-%{+YYYY.MM.dd}"
}
}kafka의 주소는 위에서 설명했던 대로 elk 네트워크에 속하는 kafka 컨테이너 서비스에 접근하는 것이므로 "kafka:29092"로 접근하도록 했다.
input과 output 사이에 필터가 필요하다면 추가해주어도 된다.
6️⃣ 라이브러리 추가
// Kafka에 로그를 전송하기 위해 Logback에 Kafka Appender를 추가
implementation 'com.github.danielwegener:logback-kafka-appender:0.1.0'
// Logstash에서 처리할 수 있는 JSON 형식으로 로그 메시지를 인코딩
implementation 'net.logstash.logback:logstash-logback-encoder:6.2'
7️⃣ src/main/resources 경로에 logback.xml을 추가
아래 xml은 로그 출력 형태, 로그 level, 출력 대상 등을 정의하는 파일로 각 부분마다 주석으로 설명을 추가해놓았다.
<configuration>
<!-- <appender> KafkaAppender 클래스를 사용하여 Kafka에 로그 메시지를 전송 -->
<appender name="LOG-KAFKA" class="com.github.danielwegener.logback.kafka.KafkaAppender">
<!-- <encoder> 로그 메시지를 Kafka가 처리할 수 있는 형식으로 변환 -->
<encoder class="com.github.danielwegener.logback.kafka.encoding.LayoutKafkaMessageEncoder">
<!-- <layout> 로그 메시지 출력 패턴 지정 -->
<layout class="ch.qos.logback.classic.PatternLayout">
<pattern>%date - %-5p %t %-25logger{5} %F:%L %m%n</pattern>
</layout>
</encoder>
<!-- <topic> Kafka에 전송될 토픽의 이름을 지정 -->
<topic>ek-log</topic>
<!-- <keyingStrategy> 키 생성 전략을 Round Robin으로 설정 (모든 파티션에 균등하게 분산되도록 메시지들이 순환적으로 파티션에 할당) -->
<keyingStrategy class="com.github.danielwegener.logback.kafka.keying.RoundRobinKeyingStrategy"/>
<!-- <deliveryStrategy> 비동기적 방식으로 로그 메시지 전송 -->
<deliveryStrategy class="com.github.danielwegener.logback.kafka.delivery.AsynchronousDeliveryStrategy"/>
<!-- <producerConfig> Kafka producer의 설정값 (순서대로, 재전송 횟수, 전송 서버 주소, 압축 타입, 데이터 전송 최대 대기 시간 -->
<producerConfig>retries=1</producerConfig>
<producerConfig>bootstrap.servers=localhost:9092</producerConfig>
<producerConfig>compression.type=snappy</producerConfig>
<producerConfig>max.block.ms=1000</producerConfig>
</appender>
<!-- <appender> 콘솔에 로그를 출력하기 위한 appender -->
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%date - %-5p %t %-25logger{5} %F:%L %m%n</pattern>
</encoder>
</appender>
<!--
<logger> elk 이름의 logger를 정의하여, INFO 레벨 메시지만 처리
<appender-ref> elk 이름의 logger가 사용할 appender 지정
-->
<logger name="elk" level="INFO" additivity="false">
<appender-ref ref="LOG-KAFKA"/>
<appender-ref ref="STDOUT"/>
</logger>
<!-- <root> 모든 logger에 대한 기본 설정을 정의 (INFO 레벨 이상의 메시지만 처리) -->
<root level="INFO">
<appender-ref ref="STDOUT"/>
</root>
</configuration>
8️⃣ log 전달 테스트 API 작성
Slf4j의 topic 옵션에 위 xml에 작성한 logger의 이름을 추가해준다.
이제 해당 logger의 이름이 붙은 Slf4j의 로그는 logstash가 받아 Elasticsearch에 저장하고 Kibana에서 모니터링 할 수 있다.
@RestController
@Slf4j(topic = "elk")
public class LogTestController {
@GetMapping("/log")
public String logTest() {
log.info("log 테스트");
return "ok";
}
}
9️⃣ 컨테이너 실행
docker-compose build
docker-compose up -d
컨테이너 실행 후 위에서 설정한 logger 이름이 @Slf4j의 topic 옵션으로 설정되어 있는 메서드를 호출해보자.
🔟 접속 확인 및 로그 확인
컨테이너가 정상적으로 실행되었다면 아래 두 주소로 접속이 되는지 확인하자.
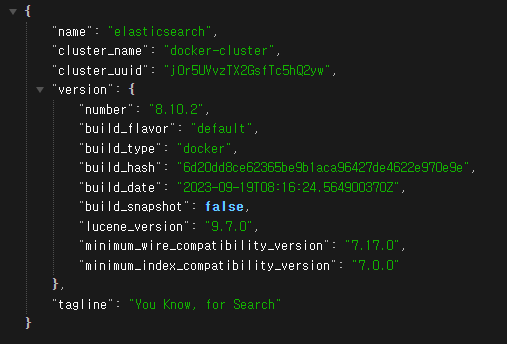
localhost:9200 : elasticsearch
elasticsearch 접속 시 아이디와 비밀번호 입력 창이 나올 것이다.
아이디는 "elastic" 비밀번호는 .env 파일에 설정한 비밀번호를 입력해주자.
입력 후 아래와 같은 json 로그가 나오면 정상 접속된 것이다.
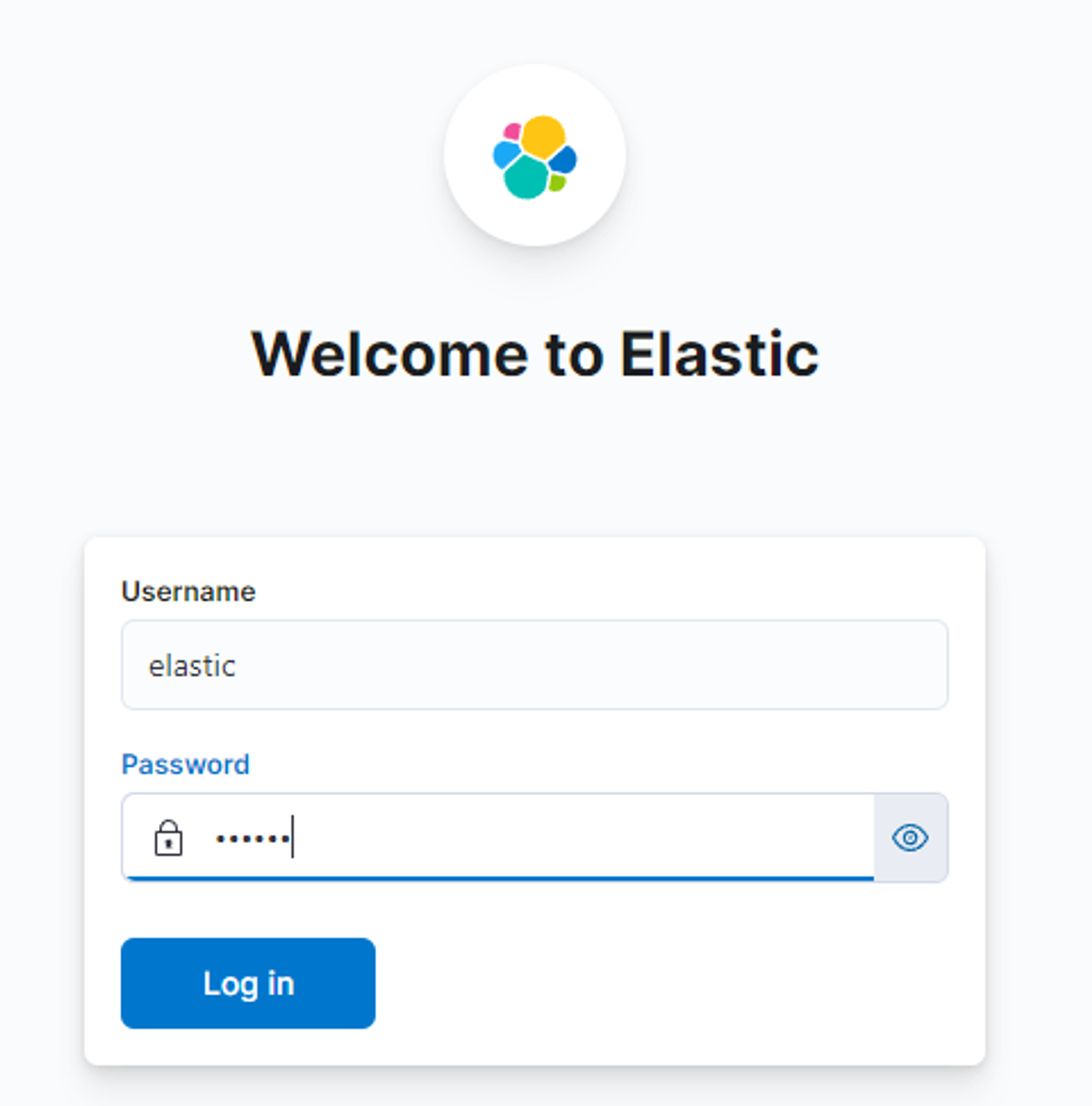
kibana에서도 아래와 같이 아이디와 비밀번호 입력 창이 나올 것이다.
똑같이 아이디 비밀번호를 입력해주면된다.
접속 후 좌측 상단의 3선 모양 클릭 후 -> Stack Management을 클릭해준다.
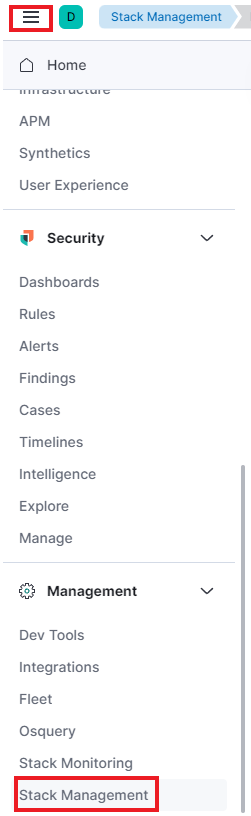
좌측의 카테고리에서 Index Mangement 항목을 클릭 후 아래처럼 logstash input에 작성한 index가 있다면 정상적으로 로그가 수집 된 것이다.
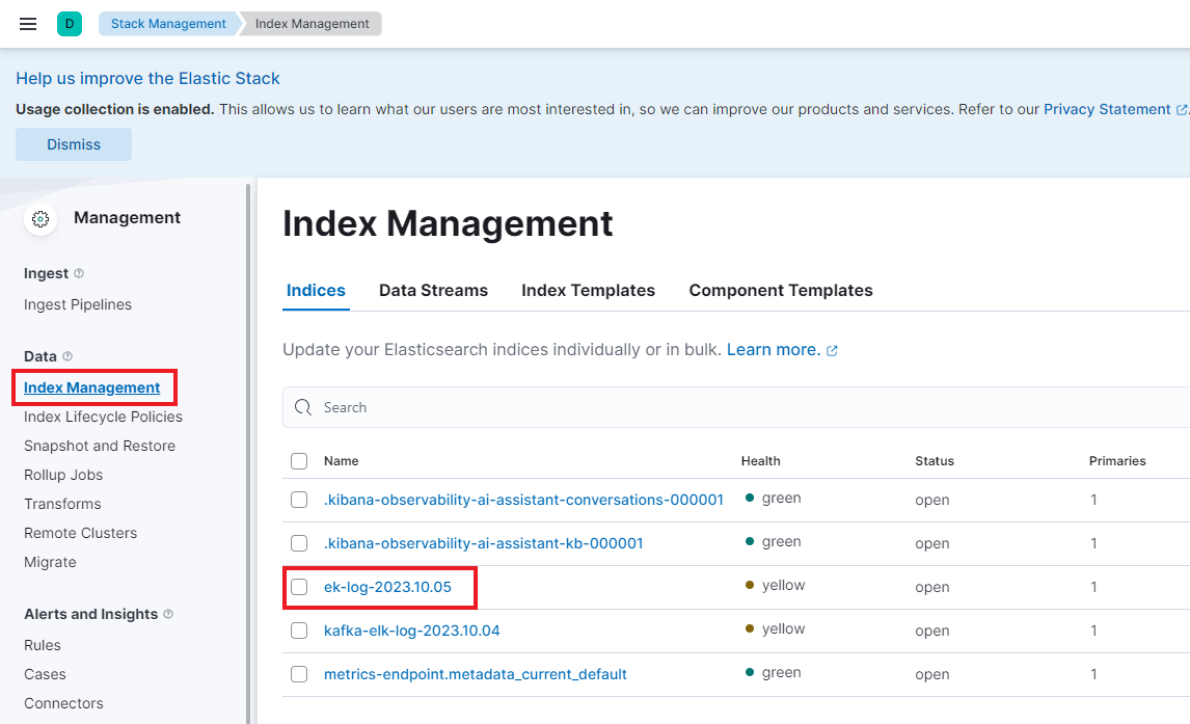
만약 설정한 인덱스가 해당 페이지에서 보이지 않는다면 로그를 수집못했거나 로그를 전송하지 못한 것이다.
필자의 경우에는 logstash에서 권한 문제로 로그를 수집하지 못했는데 해당 해결 방법은 아래 포스팅에 설명되어있다.
[ELK] Logstash 401 Unauthorized 에러
Kibana에 로그가 전달이 되질 않아서 Docker Desktop으로 logstash의 로그를 확인해보니 다음과 같은 에러가 발생했다. [2023-10-04T08:03:23,112][WARN ][logstash.outputs.elasticsearch][main] Attempted to resurrect connection to d
hstory0208.tistory.com
이 외의 오류는 컨테이너의 로그를 확인하여 해결할 수 있을 것이다.
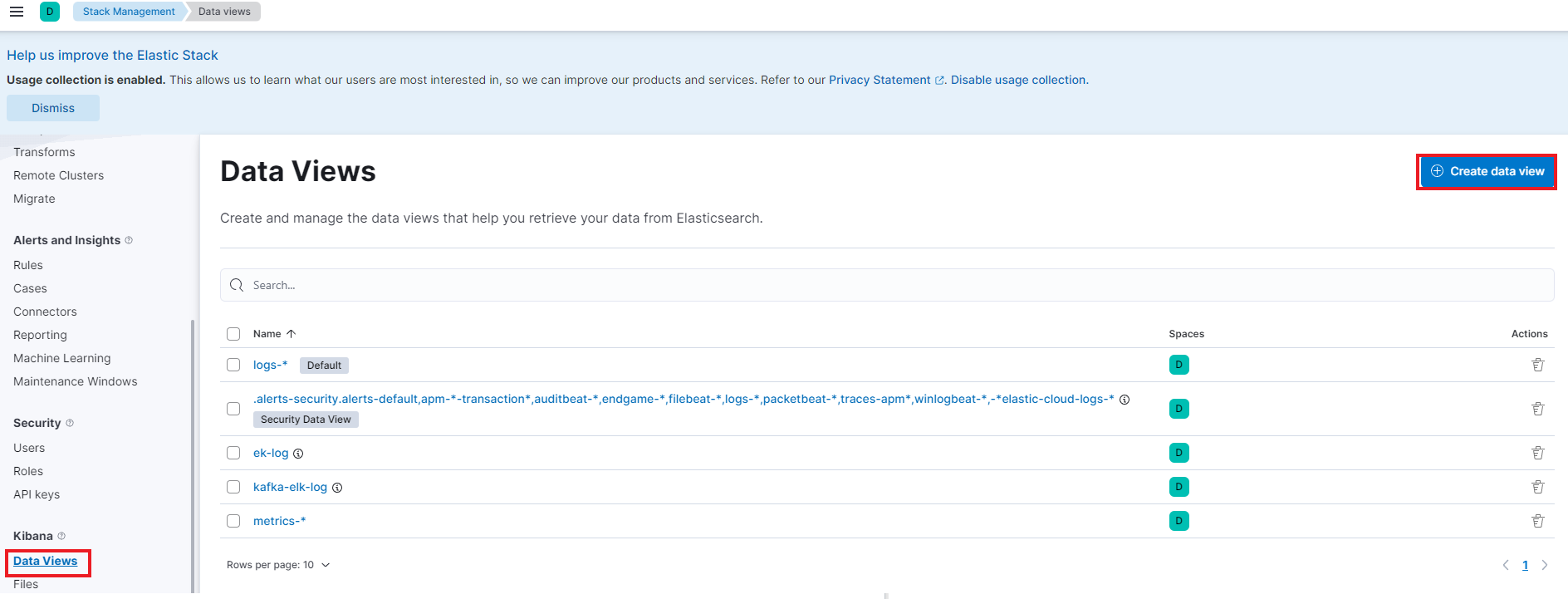
이제 해당 인덱스를 시각화하여 볼 수 있게 추가해주어야한다.
Data Views 항목으로 들어가 Create data view로 아래처럼 생성해준다. ( index pattern은 ek-log 로 시작하는 인덱스로 하였다.)

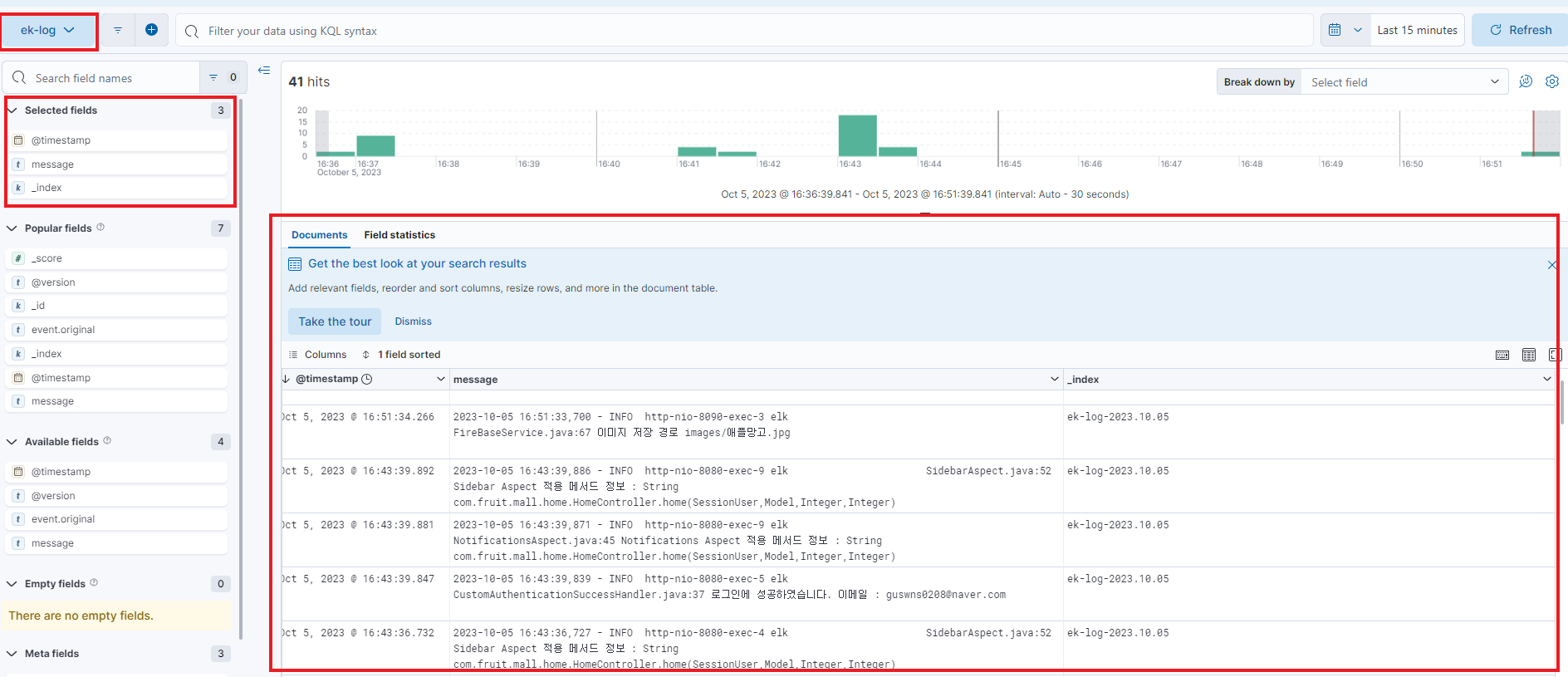
이제 다시 좌측 상단의 삼선을 클릭하고 Discover를 클릭한다.
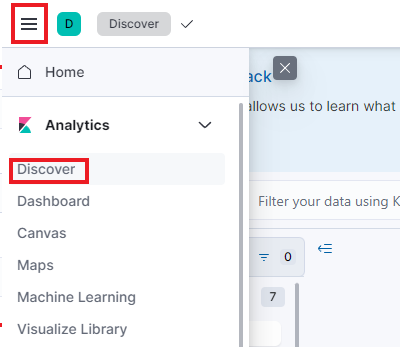
해당 페이지에서 상단의 빨간색 박스로 표시된 부분을 방금 추가한 Data View로 변경하여 보고싶은 필드를 지정하면 다음과 같이 로그들을 한눈에 파악할 수 있다.
(필자의 ek-log 같은 경우에는 회원 서버와 어드민 서버의 로그가 합쳐져 있다.)
'◼ JAVA > Spring' 카테고리의 다른 글
| [Spring] 수동 빈 등록시 사용하는 @Configuration의 특별한 기능 (0) | 2024.04.15 |
|---|---|
| [Spring] 스프링의 싱글톤 패턴과 싱글톤 컨테이너에 대해 알아보자. (0) | 2024.04.15 |
| [무중단 배포] Nginx를 사용해 EC2에 무중단 배포 적용하기 (0) | 2023.09.28 |
| [Spring AOP] 모든 페이지의 공통 헤더 영역에 공통 데이터 Model에 담아 전달 (0) | 2023.09.21 |
| [Spring] kafka와 SSE(Server Send Event)를 사용한 실시간 알림 전송 방법 (2) | 2023.09.20 |