

"@Transactional(readOnly = true)를 사용하면 성능이 좋아진다."라는 말들을 들어봤을 것이다.
그렇다면 왜 성능이 좋아지는 걸까? 그리고 항상 좋을까?에 대해 이번 포스팅에서 알아보려한다.
JPA, RDBMS 둘다 최적화가 이뤄지기 때문에 각각 어떤 성능 최적화가 이뤄지는지 알아볼 것이다.
(참고로 RDBMS는 MySQL 8.0 버전에 대해 다룬다.)
JPA 수준의 최적화
일반 트랜잭션의 경우 트랜잭션이 커밋될 때 JPA는 FlushMode.AUTO가 기본값이기 때문에 영속성 컨텍스트를 자동으로 플러시한다.
하지만 @Transactional(readOnly=true)로 설정하면 Hibernate가 FlushMode를 MANUAL로 설정하여
명시적으로 flush를 호출하지 않는 이상 flush가 자동으로 발생하지 않는다.
이와 관련해서 다양한 성능 최적화가 일어날 수 있다.
우선 flush에 대해 이해할 필요가 있다.
flush는 영속성 컨텍스트의 변경 사항을 데이터베이스에 동기화하는 작업으로, 호출 시 다음과 같은 작업이 이뤄진다.
- 변경 감지(Dirty Checking) 수행
- 쓰기 지연 방식을 사용해 변경된 엔티티의 SQL 문을 생성해놓고 및 실행
하지만 읽기 전용 트랜잭션은 위 작업이 필요 없다.
읽기 전용 옵션을 사용함으로서 FlushMode를 MANUAL로 설정되면 위 flush 작업이 수행되지 않고
변경 감지를 사용하지 않기 때문에 엔티티의 원본 상태를 저장하는 “스냅샷”도 생성하지 않아 메모리 사용량도 크게 감소한다.
즉, 읽기 전용 트랜잭션은 읽기 작업에 필요없는 작업을 제외해 성능 최적화로 쿼리 실행 속도가 향상된다.
JPA의 읽기 트랜잭션 성능 최적화 정리
1. 스냅샹 생성 생략
영속성 컨텍스트는 엔티티의 원본 상태(스냅샷)을 메모리에 유지한다.
읽기 전용 트랜잭션에서는 이러한 스냅샷을 유지할 필요가 없어 메모리 사용량이 감소한다.
@Transactional
public List<Product> findAllProducts() {
// 10,000개의 제품 로드 -> 각 제품마다 스냅샷 생성 -> 메모리 부담 큼
return productRepository.findAll();
}
@Transactional(readOnly = true)
public List<Product> findAllProducts() {
// 10,000개의 제품 로드 -> 스냅샷 생성 안함 -> 메모리 사용량 크게 감소
return productRepository.findAll();
}
2. 변경 감지(Dirty Checking) 생략
영속성 컨텍스트는 엔티티의 스냅샷과 현재 상태를 비교하여 변경된 엔티티를 찾는다.
수천 개의 엔티티가 있는 경우, 이 과정은 상당한 CPU 리소스를 소모할 수 있다.
3. SQL 생성 및 실행 생략
변경된 엔티티가 있으면 해당 변경사항을 반영하기 위한 UPDATE SQL을 생성하고
모든 쓰기/변경 작업에 대한 쿼리는 JPA는 SQL 쓰기 지연 저장소에 저장하고 커밋 시 DB에 반영한다.
쓰기 지연 저장소를 사용하는 것 자체가 개별적으로 통신하는 것이 아닌 한번의 왕복으로 모든 쿼리를 보내기 위함이지만
읽기 전용 트랜잭션은 SQL 생성 및 실행 단계 자체를 건너뛰기 때문에 네트워크 통신이 더욱 감소한다.
MySQL 수준의 최적화
MVCC 최적화
MySQL InnoDB의 경우에 READ COMMITTED와 REPEATABLE READ 격리 수준에서
데이터베이스가 각 트랜잭션을 구별하는 고유 번호인 TRX_ID를 트랜잭션마다 부여한다.
그리고 “읽기 뷰(스냅샷”)을 생성해 현재 활성 상태인 트랜잭션 목록을 담고 트랜잭션 종료까지 유지한다.
반면, 읽기 전용 트랜잭션은 TRX_ID를 부여하지 않아
다른 트랜잭션의 읽기 뷰에 현재 읽기 전용 트랜잭션으로 활성화된 TRX_ID가 포함되지 않는다.
즉, 읽기 전용 트랜잭션이 아닌 트랜잭션의 읽기 뷰의 목록이 더 작아져 더 빠르게 처리될 수 있다.
(읽기 뷰 사용은 격리 수준에 따라 다르므로 궁금하다면 아래 포스팅을 참고하면 도움이 될 수 있다.)
2024.12.01 - [◼ DB] - MySQL의 트랜잭션과 격리 수준 이해하기
또한 읽기 전용 트랜잭션은 데이터를 변경하거나 추가하지 않기 때문에
언두 로그를 생성하지 않아 언두 로그 관리 비용이 발생하지 않는다.
읽기 - 쓰기 부하 분산
일반적으로 쓰기 작업보다는 읽기 작업이 대부분이다.
Source-Replica로 레플리케이션 시 Source는 쓰기 전용, Replica는 읽기 전용 트랜잭션으로 라우팅 규칙을 달리하여
읽기와 쓰기 작업에 대한 부하 분산을 적용할 수도 있다.
버퍼풀 활용
읽기 전용 트랜잭션 일 때 특별히 최적화되는 것은 아니지만
조회 쿼리 자체는 데이터 페이지를 수정하지 않으므로 더티 페이지(dirty page) 관리 오버헤드 없이
버퍼풀에서 읽어오기 때문에 버퍼풀을 더욱 활용할 수 있다.
(버퍼 풀에 대한 설명은 아래 포스팅에서 확인할 수 있다.)
2024.12.16 - [◼ DB] - InnoDB 스토리지 엔진의 구조를 파헤쳐보자
readOnly = true는 무조건 좋나?
일반적으로 조회 전용 메서드를 사용한다면 앞서 설명한 최적화가 있기 때문에 사용하는 것이 좋긴하다.
하지만 모든 상황에서 그런 것은 아니다.
SET ~ 추가 쿼리
이건 우테코 6기 아루가 공유해줘서 새로 알게된 내용이다.
아래 카카오페이 포스팅을 참고하여 간단히 설명하자면 다음과 같다.
https://tech.kakaopay.com/post/jpa-transactional-bri/
@Transactional(readOnly=true)로 설정하면, 해당 세션의 트랜잭션을 읽기 전용을 트랜잭션으로 변경하기 위해
SET SESSION TRANSACTION READ ONLY 쿼리를 추가로 날리고
커밋 후 다시 READ WRITE 트랜잭션으로 변경하는 쿼리를 보낸다.
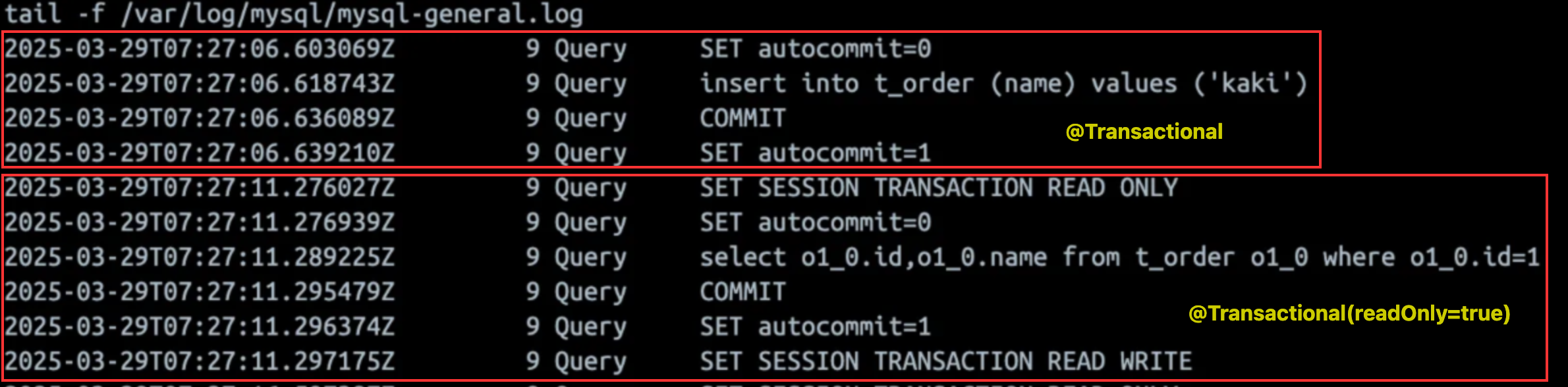
이런 추가 쿼리 발생으로 인해 위 포스팅에선 readOnly=true를 사용한 최적화 보다
트랜잭션 자체를 사용하지 않은 것이 더욱 성능이 높았다고도 테스트 결과를 보여주고 있다.
읽기만 수행하는 메서드는 어차피 원자성이 필요없다.
즉, 추가 쿼리가 발생하는 readOnly 옵션를 사용하는 것보다 오히려 트랜잭션을 사용하지 않는게 성능이 좋다는 것이다.
참고로 SimpleJPARepository 구현체에 정의된 메서드들은 기본적으로 트랜잭션이 활성화되어 있다.

만약 트랜잭션을 사용하지 않고 조회한다면 다음과 같이 JPQL을 사용해서 조회 쿼리를 만들 수 있다.
@Query("select o from Order o")
List<Order> findAllNoTx();로그를 확인해보면 SET autocommit ~, SET SETSSION ~ 쿼리가 발생하지 않는 것을 확인할 수 있다.

추가로 @Transactional는 실행되는 모든 작업을 하나의 트랜잭션으로 묶기 위해 "SET autocommit" 쿼리가 매번 반복해서 나간다.
이 또한 쓰기/변경 작업이 단일 작업이라 원자성을 보장할 필요가 없다면 @Transactional을 사용하지 않는 것이 성능측면에서 유리하다고 한다.
정리하자면, @Transactional이 필요하지 않다면 줄이는 방법으로 성능 최적화를 얻을 수 있다는 것이다.
읽기 전용 작업의 내부 로직의 처리 시간이 긴 경우
트랜잭션은 커밋이 된 후에 반납된다.
즉, 트랜잭션 유지 시간이 너무 길면 커넥션 고갈로 이어질 수 있따.
만약 읽기 전용 작업의 내부 로직의 처리 시간이 긴 경우
오히려 실제 DB에 쿼리를 보내는 레포지토리 계층에서만 트랜잭션을 사용하는 것이 나을 수도 있다는 것이다.
하지만 이 경우는 서비스 계층의 메서드에 트랜잭션을 적용하지 않기 때문에
지연 로딩을 사용한다면 OSIV 설정에 따라 결과가 다를 수 있다.
중첩 트랜잭션
트랜잭션 전파 옵션 기본값인 REQUIRES의 경우에 쓰기 트랜잭션 내부에서 읽기 전용 트랜잭션을 호출한다고 가정해보자.
이 경우 외부 트랜잭션인 쓰기 트랜잭션에 읽기 전용 트랜잭션이 참여하기 때문에 readOnly 속성은 무시되어 성능 최적화 효과가 없다.
'◼ JPA' 카테고리의 다른 글
| Batch Insert 설정 이해하기 그리고 JPA, JDBC 성능 비교 (0) | 2025.04.25 |
|---|---|
| hibernate batch 옵션 order_inserts와 order_updates는 항상 좋을까 ? (0) | 2025.04.22 |
| [Spring Data JPA] 스프링 데이터 JPA에서 페이징(Paging) 사용하기 (2) | 2023.06.26 |
| [Spring Data JPA] @EntityGraph 엔티티 그래프란? (0) | 2023.06.20 |
| [JPA] 페이징과 정렬에 대해 알아보자. (0) | 2023.06.20 |