

이번 포스팅에서는 쿼리 별로 JOIN이 어떻게 인덱스를 사용하는지에 대해 자세히 알아 볼 예정이다.
드라이빙 테이블과 드리븐 테이블
설명하기 앞서 드라이빙 테이블과 드리븐 테이블을 이해할 필요가 있다.
드라이빙 테이블 (Driving Table)
- 조인이 실행될 때 첫 번째로 액세스되는 테이블
- 선행 테이블(Outer Table)이라고도 부름
- 쿼리의 성능에 큰 영향을 미침
- 일반적으로 더 작은 결과 집합을 반환하는 테이블이 드라이빙 테이블로 선택되는 것이 유리
드리븐 테이블 (Driven Table)
- 드라이빙 테이블에서 읽힌 데이터를 기준으로 조인되는 테이블
- 후행 테이블(Inner Table)이라고도 부름
- 드라이빙 테이블의 각 레코드마다 접근됨
좀더 쉬운 이해를 위해 아래 쿼리를 살펴보자.
SELECT *
FROM employees e
JOIN dept_emp de ON e.emp_no = de.emp_no;옵티마이저는 다음과 같은 순서로 레코드를 조회하게 된다.
- 옵티마이저가 드라이빙 테이블(employees)에서 먼저 레코드를 읽음
- 읽은 각 레코드에 대해 드리븐 테이블(dept_emp)에서 매칭되는 레코드를 찾음
- 조건에 맞는 레코드들을 조인하여 결과 생성
FROM 절에 나와 있는 테이블이 항상 드라이빙 테이블이 되는 것은 아니다.
중요한 점은 옵티마이저가 통계 정보를 바탕으로 테이블의 크기, 인덱스 유무, 조건절 등을 고려하여
어떤 테이블을 드라이빙으로 할지 결정된다는 것이다.
JOIN의 순서와 인덱스
아래 쿼리를 예시로 employees 테이블과 dept_emp 테이블을 조인할 때
각 테이블의 emp_no 컬럼에 각각 인덱스가 있을 때와 없을 때의 조인 순서가 어떻게 달라지는지 알아보자.
SELECT *
FROM employees e
JOIN dept_emp de ON e.emp_no = de.emp_no;
두 컬럼 모두 각각 인덱스가 있는 경우
옵티마이저가 어떤 테이블을 드라이빙 테이블로 선택하든
옵티마이저가 선택하는 방법이 최적의 방법이 될 수 있다.
employees 테이블의 emp_no 컬럼에만 인덱스가 있는 경우
만약 dept_emp 테이블이 드리븐 테이블이 된다면
employees 테이블의 각 레코드에 대해 dept_emp 테이블을 전체 스캔(인덱스가 없으므로)해야 할 것이다.
이는 매우 비효율적인 방식이기 때문에 옵티마이저는 항상 dept_emp을 드라이빙 테이블로 선택해 먼저 읽고
각 레코드에 대해 employees 테이블의 인덱스를 사용하여 검색한다.
즉, 인덱스가 있는 테이블을 드리븐 테이블로 사용한다.
두 컬럼 모두 인덱스가 없는 경우
어느 테이블을 드라이빙 테이블로 선택하더라도 테이블 풀 스캔이 발생하기 때문에
레코드 건수가 적은 테이블을 드라이빙 테이블로 선택하는 것이 효율적일 것일 수 있다.
옵티마이저는 통계 기반으로 적절히 드라이빙 테이블을 선택하게 된다.
JOIN 컬럼의 데이터 타입
조인 컬럼 간에 비교에서도 각 컬럼의 데이터 타입이 일치하지 않으면 인덱스를 효율적으로 이용할 수 없다.
CREATE TABLE orders (
order_id INT,
customer_number VARCHAR(10),
INDEX (customer_number)
);
CREATE TABLE customers (
id INT,
number INT,
INDEX (number)
);
SELECT *
FROM orders o
JOIN customers c ON o.customer_number = c.number; -- VARCHAR와 INT를 비교이 쿼리의 경우에는 문자 타입인 customer_number을 숫자로 변환해 비교를 수행해
인덱스의 변형이 필요하기 때문에 customer_number의 인덱스를 제대로 사용할 수 없고
내부적으로 조인 버퍼를 사용하는 것을 볼 수 있다.

또한 컬럼 타입은 같지만 character set이 달라도 문제가 된다.
CREATE TABLE tb_test1(
user_id INT,
user_type CHAR(1) COLLATE utf8mb4_general_ci,
PRIMARY KEY(user_id)
);
CREATE TABLE tb_test2(
user_type CHAR(1) COLLATE latin1_general_ci,
type_desc VARCHAR(10),
INDEX ix_usertype (user_type)
);
EXPLAIN SELECT *
FROM tb_test1 tb1, tb_test2 tb2
WHERE tb1.user_type = tb2.user_type;
이 경우에도 tb_test2의 idx_usertype 인덱스를 사용하지 않고 조인 버퍼를 사용한 것을 볼 수 있다.
옵티마이저는 드리븐 테이블이 인덱스 레인지 스캔을 사용하지 못하고
드리븐 테이블의 풀 테이블 스캔이 필요한 것을 알고 조금이라도 빨리 실행되도록 하고자
조인 버퍼를 활용한 해시 조인을 이용하는 것이다.
조인 버퍼는 join_buffer_size 설정에 따라 제한되며 메모리를 사용하기 때문에 조인이 완료되면 조인 버퍼는 바로 해제된다.
하지만 큰 데이터의 경우 예상치 못한 메모리 부족이 발생할 수 있기 때문에
가능하면 인덱스를 활용할 수 있는 구조로 설계하는 것이 좋을 것이다.
OUTER JOIN 성능과 주의사항
아래 쿼리를 한번 보자.
(departments.dept_no 인덱스 O, employees emp_no 인덱스 PK, dept_emp emp_no 인덱스 X)
SELECT *
FROM employees e
LEFT JOIN dept_emp de ON de.emp_no=e.emp_no
LEFT JOIN departments d ON d.dept_no=de.dept_no AND d.dept_name='Development';옵티마이저는 절대 OUTER JOIN되는 테이블을 드라이빙 테이블로 선택하지 못한다.
따라서 employees 테이블을 드라이빙 테이블로 선택한다.

이너 조인을 사용한다면 다음과 같이 WHERE 조건으로 departments 테이블의 레코드 수를 줄이고
이 테이블을 드라이빙 테이블로 사용해 효율적인 쿼리를 작성할 수 있다.
SELECT *
FROM departments d
JOIN dept_emp de ON d.dept_no = de.dept_no
JOIN employees e ON de.emp_no = e.emp_no
WHERE d.dept_name = 'Development';이 쿼리에서 옵티마이저는 WHERE 조건을 먼저 확인해서 departments 테이블에서 'Development' 부서만 먼저 찾고
그 결과를 가지고 다른 테이블과 조인을 수행하기 때문에
더 적은 데이터로 조인을 수행할 수 있어 효율적이다.
꼭 필요한 경우가 아니라면 이너 조인을 사용하는 것이
드라이빙 테이블을 적절히 선택하도록 유도해 쿼리의 성능도 향상시킬 수 있을 것이다.
또 주의할점은 OUTER JOIN에서 조인되는 테이블에 대한 조건을 WHERE 절에 함께 명시하는 것이다.
SELECT *
FROM employees e
LEFT JOIN dept_manager mgr ON mgr.emp_no = e.emp_no
WHERE mgr.dept_no = 'd001';위 처럼 OUTER JOIN되는 테이블에 대한 조건을 WHERE 절에 함께 명시하는 쿼리를 작성하면
옵티마이저가 LEFT JOIN을 다음과 같이 INNER JOIN으로 변환해 실행해버린다.
SELECT *
FROM employees e
INNER JOIN dept_manager mgr ON mgr.emp_no = e.emp_no
WHERE mgr.dept_no = 'd001';이렇게 변환하는 이유는 다음과 같다.
- LEFT JOIN은 employees의 모든 행을 보존하고, 매칭되지 않는 dept_manager 컬럼들은 NULL로 채움
- 하지만 WHERE mgr.dept_no = 'd001' 조건으로 인해 mgr.dept_no가 NULL인 행은 모두 제거됨
- 결과적으로 dept_manager와 매칭되는 행만 남게 됨
정상적인 OUTER JOIN이 되게 만드려면 다음 쿼리와 같이 WHERE 절의 조건을 ON 절로 옮겨야한다.
SELECT *
FROM employees e
LEFT JOIN dept_manager mgr ON mgr.emp_no = e.emp_no AND mgr.dept_no = 'd001';
하지만 이례적으로 다음과 같이 안티 조인 사용 시에
OUTER JOIN되는 테이블에 대한 조건을 WHERE 절에 함께 명시할 순 있다.
-- 사원 중 매니저가 아닌 직원을 찾는 쿼리 (ANTI JOIN)
SELECT *
FROM employees e
LEFT JOIN dept_manager dm ON dm.emp_no = e.emp_no
WHERE dm.emp_no IS NULL -- dept_manager의 emp_no 컬럼이 NULL인 레코드만 조회
LIMIT 10;실행 계획으로 인한 정렬 흐트러짐 (중첩 루프 조인과 해쉬 조인)
MySQL 8.0 버전 이전에는 중첩 루프 조인만 가능했지만 이후부터는 해시 조인 방식이 도입됐다.
중첩 루프 조인은 드라이빙 테이블의 각 행에 대해 드리븐 테이블을 순차적으로 검색하는 방식이다.
결과는 드라이빙 테이블을 읽은 순서가 그대로 최종 결과에 반영된다.
하지만 해시 조인 방식은 정렬 순서가 드라이빙 테이블을 읽는 순서와 다르게 출력된다.
EXPLAIN SELECT e.emp_no, e.first_name, e.last_name, de.from_date
FROM dept_emp de, employees e
WHERE de.from_date > '2001-10-01' AND e.emp_no < 10005;위 쿼리를 실행하면 employees 테이블을 드라이빙 테이블로 선택하고
dept_emp 테이블을 드리븐 테이블로 선택해 해시 조인 방식은 방식으로 데이터를 찾고 있다.

그리고 실제로는 다음과 같이 emp_no로 정렬되지 않고 뒤죽박죽인 상태로 조회가 된다.
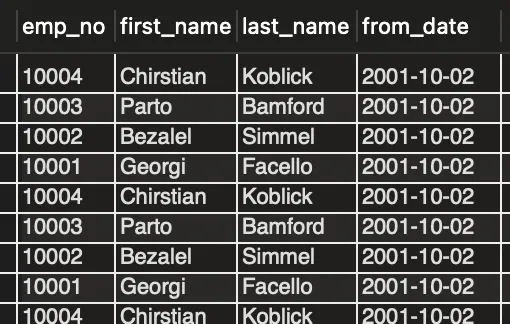
쿼리 힌트로 중첩 루프 조인을 강제하면 다음과 같이 emp_no가 정렬된 순서로 조회가 되는 것을 볼 수 있다.
SELECT /*+ JOIN_FIXED_ORDER() */
e.emp_no, e.first_name, e.last_name, de.from_date
FROM dept_emp de, employees e
WHERE de.from_date > '2001-10-01' AND e.emp_no < 10005;
실행 계획은 항상 미리 예측할 수 없고 MySQL 옵티마이저에 의해 그때 그때 상황마다 달라진다.
그러므로 정렬된 결과가 필요하다면 드라이빙 테이블의 순서에 의존하기 보다는
ORDER BY 절을 명시하는 것이 좋을 것이다.
최적화 조인
일반적인 INNER, OUTER JOIN외에 MySQL에서는 JOIN 성능 최적화를 위한 특별한 조인들이 있다.
이 최적화 조인인 세미 조인, 해쉬 조인, 지연된 조인, 레터럴 조인들은 아래 포스팅에서 다룬다.
2025.01.28 - [◼ DB] - MySQL의 최적화 조인들에 대해 알아보자
참고자료
- Real MySQL 8.0 2권
'◼ DB' 카테고리의 다른 글
| MySQL의 최적화 조인들에 대해 알아보자 (0) | 2025.01.28 |
|---|---|
| MySQL의 내장 함수 종류에 대해 알아보자 (1) | 2025.01.23 |
| MySQL의 쿼리 작성 기초 및 연산자, 타입별 쿼리 작성법 정리 (2) | 2025.01.23 |
| MySQL의 인덱스 종류에 대해 알아보자. (1) | 2025.01.23 |
| MySQL의 인덱스 스캔에 대해 알아보자 (feat. 커버링 인덱스) (0) | 2024.12.31 |