

DTO를 조회 하되, 그 안에도 엔티티가 있을 경우 DTO로 변환해서 사용해야한다.
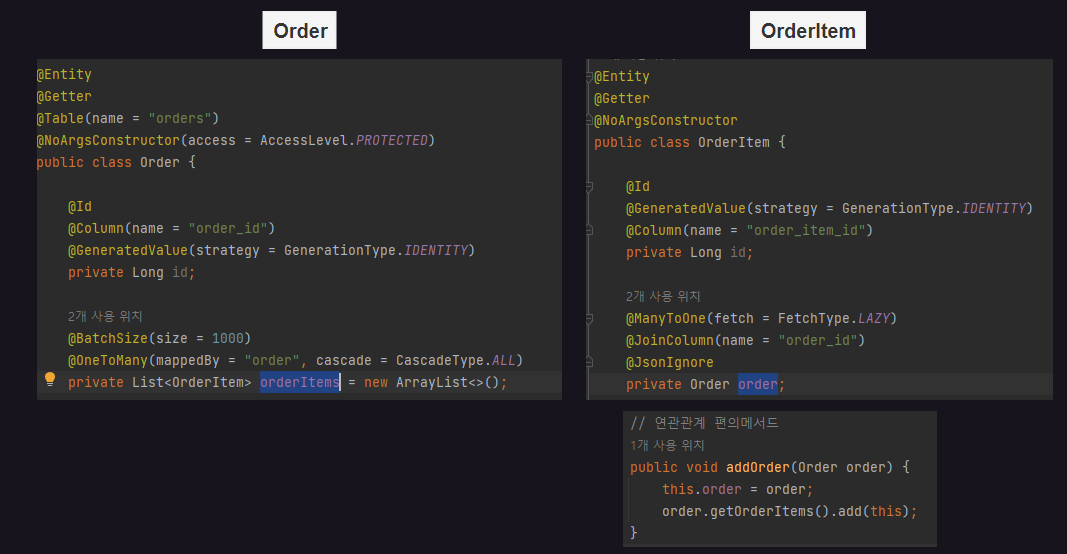
아래 그림은 Order와 OrderItem 엔티티의 일부 코드로 "1 : 다" 양방향 관계를 갖고 있는 것을 볼 수 있다.
이 전 포스팅에서 엔티티를 직접 반환하면 안되는이유에 대해 알아봤었다.
[Spirng/JPA] Dto와 Entity를 분리해서 사용하는 이유
프로젝트를 진행하거나 강의, 책을 보면 항상 엔티티를 직접 반환하지말고 DTO로 변환하여 반환하라는 말을 접하거나 보았을 것이다. 하지만 단순히 "아 ~ 그렇게 하라니까 그렇게 해야지" 보다
hstory0208.tistory.com
컬렉션도 마찬가지다. 컬렉션도 엔티티를 DTO로 변환해서 반환해야한다.
Order와 OrderItem이 연관관계를 갖고 있는 것 처럼 Order의 값을 갖고오는데 Order안에 있는 OrderItems 컬렉션을 갖고오기 위해서
OrderItems 도 DTO로 변환해서 사용해야 하는 것이다.
Order
@Getter
public class OrderDto {
private Long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private Address address;
private List<OrderItemDto> orderItems;
public OrderDto(Order o) {
this.orderId = o.getId();
this.name = o.getMember().getName();
this.orderDate = o.getOrderDate();
this.orderStatus = o.getStatus();
this.address = o.getMember().getAddress();
this.orderItems = o.getOrderItems().stream()
.map(orderItem -> new OrderItemDto(orderItem))
.collect(Collectors.toList());
}
}
OrderItem
@Getter
public class OrderItemDto {
private String itemName;
private int orderPrice;
private int count;
public OrderItemDto(OrderItem orderItem) {
this.itemName = orderItem.getItem().getName();
this.orderPrice = orderItem.getOrderPrice();
this.count = orderItem.getCount();
}
}
fetch join 시 발생하는 문제점
위 두 엔티티는 지연로딩으로 설정되어 있고, 양방향 관계를 갖는다.
따라서 Order 엔티티를 조회했을 경우 수많은 쿼리가 나가게 된다. (N + 1 문제)
그래서 이 경우에 fetch join을 사용해 SQL을 한번만 실행하도록 최적화를 할 수 있다.
하지만 여기서 문제가 발생한다.
컬렉션 fetch join시 데이터 중복 발생
만약 Order에는 2개의 행이 있고, OrderItems에는 4개의 행이 있다고 가정해보자.
이 때 Order를 조회하면 기대하는 행의 수는 2개이지만 4개의 행이 조회가 된다.

이 이유는 동일한 객체가 Json 데이터가 중복되어 전달되었기 때문인데
이 문제를 해결 하기 위해서 DISTINCT 키워드를 앞에 붙여주면 해결가능하다.
참고로 컬렉션 페치 조인은 1개만 사용할 수 있다.
컬렉션 둘 이상에 페치 조인을 사용하면 데이터가 부정합하게 조회될 수 있다.
페이징 불가
컬렉션을 fetch join하는 순간 페이징이 불가능해진다.
컬렉션을 페치 조인하면 1 : 다 조인이 발생하므로 데이터가 예측할 수 없이 증가한다.
1 : 다에서 1을 기준으로 페이징을 하는 것이 목적인데 데이터는 다(N)를 기준으로 row(행)가 생성된다.
Order를 기준으로 페이징 하고 싶은데, 다(N)인 OrderItem을 조인하면 OrderItem이 기준이 되어 버린다.
이 경우 하이버네이트는 경고 로그를 남기고 모든 DB 데이터를 읽어서 메모리에서 페이징을 시도하게 되고 최악의 경우 장애가 발생한다.
( 1 : 1 관계는 fetch join을 해도 문제가 발생하지 않는다. )
fetch join을 사용하면서 페이징 적용
컬렉션 엔티티를 조회하고 페이징 기능까지 함께 사용하려면 어떻게 해야할까?
방법
- 먼저 ToOne (OneToMany, OneToOne) 관계를 모두 페치 조인한다. (ToOne 관계는 row수를 증가시키지 않기 때문에 페이징 쿼리에 영향을 주지 않는다. 즉, 데이터 중복 문제 X)
- 컬렉션은 지연 로딩으로 조회한다. (fetch 조인 사용 x)
- 지연 로딩 성능 최적화를 위해 hibernate.default_batch_fetch_size 또는 @BatchSize 를 적용한다.
✏ 이 옵션들을 사용하면 컬렉션이나, 프록시 객체를 한꺼번에 설정한 size IN 키워드를 사용해 조회한다.
- hibernate.default_batch_fetch_size: 글로벌 설정 ( 주로 사용 )
- @BatchSize: 어노테이션을 붙여 개별 최적화
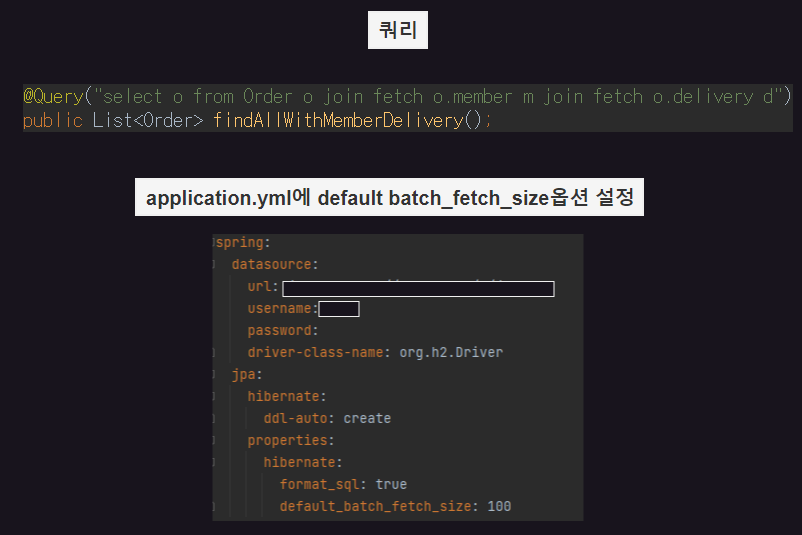
hibernate.default_batch_fetch_size 사이즈 설정하기
default_batch_fetch_size 의 크기를 어떻게 설정해야 하는지 고민이 있을 수 있다.
적당한 사이즈를 골라야 하는데, 100~1000 사이를 선택하는 것을 권장한다.
이 수치는 SQL IN 절을 사용하는데, 데이터베이스에 따라 IN 절 파라미터를 1000으로 제한하기도 한다.
1000으로 잡으면 한번에 1000개를 DB에서 애플리케이션에 불러오므로 DB에 순간 부하가 증가할 수 있다.
하지만 애플리케이션은 100이든 1000이든 결국 전체 데이터를 로딩해야 하므로 메모리 사용량이 같다.
1000으로 설정하는 것이 성능상 가장 좋지만, 결국 DB든 애플리케이션이든 순간 부하를 어디까지 견딜 수 있는지로 결정하면 된다.
'◼ JPA' 카테고리의 다른 글
| [JPA] 페이징과 정렬에 대해 알아보자. (0) | 2023.06.20 |
|---|---|
| [Spring Data JPA] 쿼리 생성 기능과 반환 타입 (0) | 2023.06.20 |
| JpaRepository를 상속한 인터페이스가 구현체가 없이 동작하는 이유 (0) | 2023.06.19 |
| [JPA] @Modifying이란? 그리고 주의할점 (벌크 연산) (0) | 2023.06.12 |
| [JPA] JPQL의 fetch join(패치 조인)이란? (2) | 2023.06.12 |