

현재 필자의 PDF 뷰어 프로그램은 PDF 책 파일을 열면 다음과 같이 해당 페이지의 이미지를 보여준다.
(JavaFX GUI 라이브러리 + Spring Boot 사용)
페이지 이동은 다음과 같이 이동할 수 있는 상황이다.

실제로 프로그램을 사용해보던 중 다음과 같은 문제가 있었다.
페이지 이동 시 마다 이미지 렌더링 속도가 0.65초로 나왔고 이는 실 사용에서 버벅임이 느껴질 정도로 크게 체감됐다.
이 문제를 해결하기 위해 이미지를 캐싱해 렌더링 속도를 최적화하기로 했다.
최적화하기 앞서 사용 패턴을 다음과 같이 분석해봤다.
- 이전에 봤던 페이지들을 번갈아가며 이동한다.
- 한 페이지씩 이동하며 페이지를 확인한다.
이제부터 이 패턴을 바탕으로 어떻게 캐싱을 적용해 렌더링 속도를 최적화 했는지 포스팅하려한다.
LinkedHashMap을 사용해 LRU 캐시 적용하기
LinkedHashMap을 사용해 LRU 캐싱 알고리즘을 적용했다.
(스프링의 카페인 캐시도 사용할 수 있었지만, LRU 캐싱을 구현하는 것은 간단했기에 직접 구현함으로써 최대한 가볍게 만들고 싶었고 LRU 캐시가 의도한데로 작동하는지 직접 테스트하고 싶었다.)
@Slf4j
@Component
public class PDFImageCacheManager {
private static final int MAX_CACHE_SIZE = 20;
private final Map<Integer, Image> pageCache = new LinkedHashMap<>(MAX_CACHE_SIZE, 0.75f, true) {
@Override
protected boolean removeEldestEntry(Map.Entry<Integer, Image> eldest) {
return size() > MAX_CACHE_SIZE;
}
};
public Image getCacheImageFrom(int pageIndex) {
return pageCache.get(pageIndex);
}
public void addCacheOf(int pageIndex, Image image) {
pageCache.put(pageIndex, image);
}
public void clear() {
pageCache.clear();
}
}LRU 캐싱 알고리즘 구현을 위한 LinkedHashMap의 생성자 파라미터를 설명하면 다음과 같다.
1번째 파라미터 : initialCapacity
해시맵의 초기 크기를 설정한다.
필자가 초기 크기를 20으로 설정한 이유는 다음과 같다.
모든 페이지를 캐싱 해놓으면 좋겠지만 이미지 렌더링 시 zoom 크기에 따라 아래 크기의 메모리를 차지했다.
page 8 | size 610 x 818 | memory usage: 1.90MB
page 9 | size 812 x 1090 | memory usage: 3.38MB // Default Zoom Factor
page 10 | size 1015 x 1363 | memory usage: 5.28MB때문에 보통 300페이지는 기본으로 넘는 PDF 책의 경우에는 이미지 때문에 너무 많은 메모리를 차지할 수 있는 문제가 있었고
전체 페이지 이미지를 캐싱 시 아래 처럼 메모리 사용량이 너무 컸다.

필자는 8GB RAM 컴퓨터에서도 해당 프로그램을 사용할 수 있길 원했다. (아주 가벼운 뷰어 프로그램을 만들고 싶었음)
그래서 캐시 사이즈를 고정하기로 했고, 이미 본 이미지 뿐 아니라 인접 페이지까지 캐싱하기 위해 20개의 이미지를 캐싱하도록 결정했다.
캐시 사이즈를 20으로 설정 시에는 다음과 같이 프로그램 메모리 사용량이 확연히 내려갔다.

2번째 파라미터 : loadFactor
해시맵의 리사이징(재할당) 임계값을 결정한다. (임계값 = 내부 테이블 크기 × 로드 팩터)
HashMap의 기본 로드 팩터는 0.75다.
항목 수가 이 임계값을 초과하면 재해싱이 발생해 내부 테이블 크기가 2배로 증가하고 모든 기존 항목이 새 테이블에 다시 해시되어 배치된다.
그럼 20 * 0.75 = 15 만큼 테이블이 차면 재해싱이 발생할까?
그렇지 않다.
재밌는 점은 HashMap의 내부 테이블은 입력한 initialCapacity보다 더 큰 크기의 사이즈로 만든다.
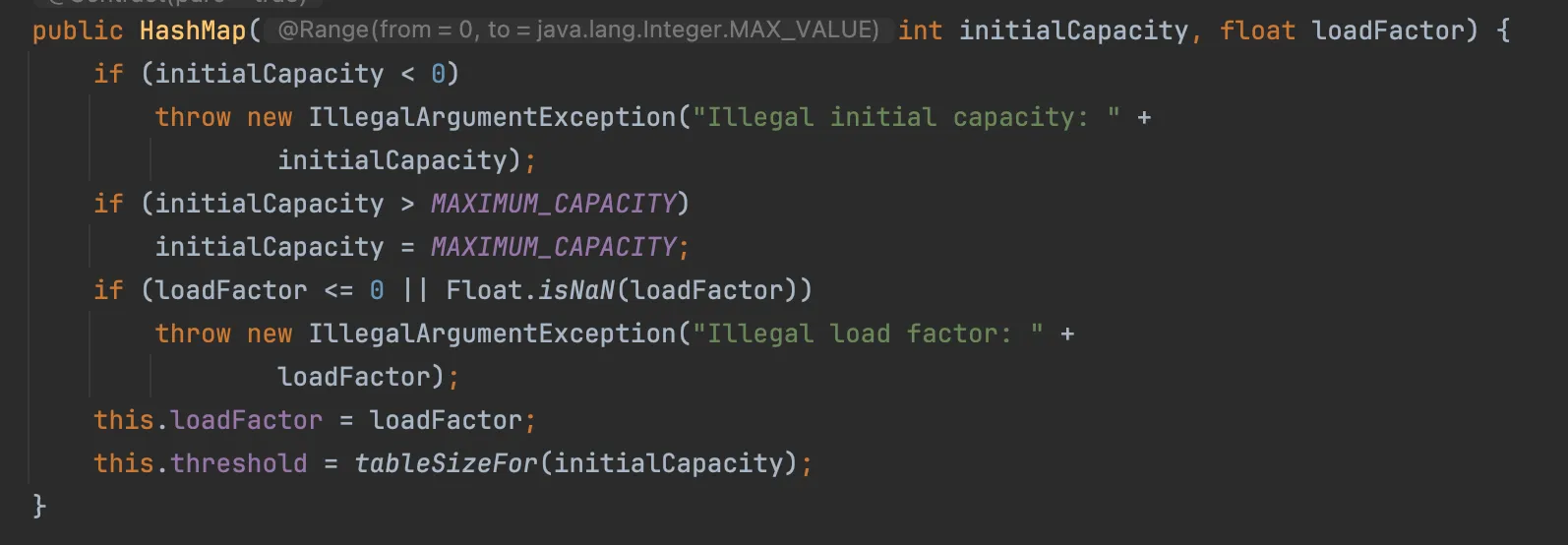

좀 더 자세히 설명하자면 initialCapacity을 20으로 설정하면 20보다 크거나 같은 가장 작은 2의 거듭제곱을 찾는다.
16은 20보다 작고, 32는 20보다 크다.
따라서 테이블 크기는 32(2⁵)가 된다.
이는 해시 함수와 인덱스 계산의 효율성을 위한 설계라고 한다.
더 자세히 알고 싶다면 아래 블로그에 설명이 잘되있으니 참고하면 좋을 것 같다.
3번째 파라미터 : accessOrder (true)
맵 항목들의 순서 결정 방식을 설정한다.
true면 가장 최근에 접근한 항목이 반복자의 마지막에 위치한다.
false면 삽입 순서로 맵에 추가된 순서대로 항목이 유지된다.
이 부분을 true로 설정하는 것이 LRU 캐시 구현의 핵심이다.
removeEldestEntry 오버라이딩 메서드
추가로, removeEldestEntry 메서드는 HashMap에 새 항목이 추가될 때마다 자동으로 호출되어 가장 오래된 항목을 제거할지 결정한다.
위 구현에서는 MAX_CACHE_SIZE를 초과하면 해당 메서드가 true를 반환한다.
accessOrder 옵션과 연관지어 보면 다음과 같다.
// accessOrder = false
[A, B, C] (순서: A -> B -> C)
get(B) 호출: [A, B, C] (순서 변화 없음: A -> B -> C)
put(D) 호출: [B, C, D] (A가 가장 오래된 항목으로 제거됨)
// accessOrder = true
[A, B, C] (순서: A -> B -> C)
get(B) 호출: [A, B, C] (순서 변경: A -> C -> B)
put(D) 호출: [C, B, D] (A가 가장 오래 사용하지 않은 항목으로 제거됨)페이지 이미지 렌더링 시 캐싱 적용
이 구현은 “이전에 봤던 페이지들을 번갈아가며 이동한다.” 패턴을 위한 구현이다.
페이지를 이동할 때마다 렌더링 함수를 호출하고, 렌더링 함수는 아래 함수를 호출한다.
@Slf4j
@Service
@RequiredArgsConstructor
public class PDFRender {
private final PDFImageCacheManager cacheManager;
...
public Image getPageImage(int pageIndex) throws IOException {
Image cachedImage = cacheManager.getCacheImageFrom(pageIndex);
if (cachedImage != null) {
return cachedImage;
}
float scale = RENDER_SCALE * (float) viewerState.getZoomFactor().get();
BufferedImage bufferedImage = pdfRenderer.renderImage(pageIndex, scale, ImageType.RGB);
Image image = SwingFXUtils.toFXImage(bufferedImage, null);
cacheManager.addCacheOf(pageIndex, image);
return image;
}
...
}- 해당 페이지 인덱스로 캐싱된 이미지가 있으면 그대로 반환한다.
- 없다면 현재 줌 크기와 렌더링 크기로 이미지 크기를 구해 저장하고 캐싱한다.
인접 페이지 이미지를 백그라운드로 캐싱 적용
이 부분은 “한 페이지씩 이동하며 페이지를 확인한다.” 패턴을 위한 구현이다.
우선 백그라운드로 인접 페이지를 캐싱하기 위해 다음과 같이 비동기 설정을 적용했다.
@EnableAsync
@Configuration
public class AsyncConfig implements AsyncConfigurer {
@Bean
public Executor pdfExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor(); // Spring에서 제공하는 스레드 풀 구현체
int corePoolSize = Runtime.getRuntime().availableProcessors();
executor.setCorePoolSize(corePoolSize);// 기본적으로 유지되는 스레드 수를 설정 (시스템의 CPU 코어 수를 기준으로 설정)
executor.setMaxPoolSize(corePoolSize * 2); // 스레드 풀의 최대 크기를 설정
executor.setQueueCapacity(100); // 스레드 풀의 작업 큐 용량을 설정
executor.setThreadNamePrefix("PDF-viewer-"); // 생성되는 스레드 이름에 접두사를 설정
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy()); // 큐가 가득 차고 모든 스레드가 사용 중일 때 작업 거부 처리 정책을 설정 (CallerRunsPolicy는 작업을 요청한 스레드에서 해당 작업을 직접 실행)
executor.initialize();
return executor;
}
// 비동기 메서드 실행 중 발생하는 예외를 처리하기 위한 핸들러
@Override
public AsyncUncaughtExceptionHandler getAsyncUncaughtExceptionHandler() {
return (exceptionHandler, method, params) -> {
log.error(
"Exception occurred while executing asynchronous method - method: {}",
method.getName(),
exceptionHandler
);
};
}
}
그리고 인접 페이지를 로딩하기 위한 메서드에 다음과 같이 @Async를 적용했다.
@Slf4j
@Service
@RequiredArgsConstructor
public class PDFAsyncService {
private final PDFImageCacheManager imageCacheManager;
@Async
public void preloadAdjacentPages(PDFViewerState viewerState, PDFRenderer pdfRenderer) {
int currentPage = viewerState.getCurrentPage().get();
int totalPages = viewerState.getTotalPages().get();
double zoomFactor = viewerState.getZoomFactor().get();
try {
if (currentPage + 1 < totalPages) {
renderAndCacheImage(pdfRenderer, currentPage + 1, zoomFactor);
}
if (currentPage > 0) {
renderAndCacheImage(pdfRenderer, currentPage - 1, zoomFactor);
}
} catch (Exception exception) {
log.warn("Adjacent page preload Error", exception);
}
}
public void renderAndCacheImage(PDFRenderer pdfRenderer, int pageIndex, double zoomFactor) throws IOException {
Image cachedImage = imageCacheManager.getCacheImageFrom(pageIndex);
if (cachedImage != null) {
return;
}
float scale = 2.0f * (float) zoomFactor;
BufferedImage bufferedImage = pdfRenderer.renderImage(pageIndex, scale, ImageType.RGB);
Image image = SwingFXUtils.toFXImage(bufferedImage, null);
imageCacheManager.addCacheOf(pageIndex, image);
}
}preloadAdjacentPages()는 페이지를 렌더링하는 메서드가 호출 될때마다 현재 페이지를 로딩할 때 함께 호출되며
백그라운드로 인접한 1개의 페이지들을 미리 캐싱해둔다.
렌더링 성능 최적화 결과
페이지 이미지 렌더링 시 캐싱과 인접 페이지 이미지 백그라운드로 캐싱한 결과 얼마나 최적화가 이뤄졌을까?
| 캐싱 여부 | 실행 시간 |
| 캐싱 적용 X | 0.65초 |
| 캐싱 적용 O | 2.542E-6초 = 0.000002542초 |
성능 향상 배수를 계산해보면 0.65 / 0.000002542로 무려 255,704배가 개선됐다.
성능 개선율은 ((0.65 - 0.000002542) × 100) / 0.000002542로 25,570,318% 개선됐다.
실제로 사용하는데도 문제 없이 PDF 문서를 볼 수 있었고 엄청난 향상 수치에 놀라웠다.
GUI 프로그램은 처음 만들어봤는데 여기서 발생할 수 있는 문제점을 개선하는 것도 재미있는 경험이었다.
'◼ Spring' 카테고리의 다른 글
| 분산 서버 환경에서 스케줄링 작업 중복 실행 제어하기 (0) | 2025.03.14 |
|---|---|
| REQUIRES_NEW에 대한 오해와 주의할 점 (1) | 2024.11.26 |
| 분산락을 적용해 동시성 문제 해결하기 (3) | 2024.11.20 |
| 외부 API 의존성 분리 및 장애 대응 체계 구축하기 (0) | 2024.11.19 |
| [Spring] TestContainers로 Redis 테스트하기 (2) | 2024.11.14 |