

이미지 렌더링 속도를 최적화하기 위해 LRU 캐시를 구현하여 이미지를 메모리에 저장하고 있었다.
2025.04.26 - [◼ Spring] - GUI 프로그램에 LRU 캐시 적용으로 렌더링 속도 최적화하기
하지만 이미지 하나의 크기는 2MB로 생각보다 많은 용량을 차지하고 있었고
프로그램의 메모리 사용량을 더욱 최적화하기 위해 이미지 압축 방법을 알아보고 이를 적용해보려 한다.
우선 압축 방식은 ‘손실 압축’과 ‘무손실 압축 방식’이 존재한다.
압축을 적용하기 전 각각에 대해 먼저 알아보자.
손실 압축
손실 압축은 압축 과정에서 일부 데이터를 의도적으로 제거하여 높은 압축률을 달성하는 방식이다.
사람의 눈은 생각보다 밝기 구분은 잘하지만 섬세한 색상 정보 차이는 잘 구분하지 못한다.
예시로 아래의 색상별 차이가 보이는가?

rgb 값이 달라 미세한 차이는 있지만 과학적으로 인간의 눈은 이를 명확하게 구분하지 못한다.
즉, 손실 압축은 인간의 인지적 특성을 활용해 중요하지 않은 정보를 제거하는 방식이다.
대표적인 이미지 손실 압축 포맷으로는 ‘JPG / JPEG’가 있다.
손실 압축 시에는 Quality로 압축률을 설정하게 된다.
Quality는 1 ~ 100의 범위의 값으로 커질 수록 압축률이 줄어들어 손실율이 감소하게 된다.
반대로 작아질수록 압축률은 높아져 크기는 많이 줄지만 화질 저하가 생긴다.
손실 압축 특징
- 원본 데이터의 일부 정보 손실
- 압축 해제 시 원본과 다른 데이터 복구
- 인간의 시각적 인지 특성을 활용한 인간이 인지하기 어려운 정보를 선별적으로 제거
- 높은 압축률 달성 가능
무손실 압축
무손실 압축은 압축된 데이터를 원본과 완전히 동일하게 복원할 수 있는 압축 방식이다.
압축 과정에서 어떤 정보도 손실되지 않으며, 압축 해제 후 원본 데이터와 비트 단위로 완전히 일치한다.
손실 없이도 압축이 되는 원리는 다음과 같은 알고리즘을 사용해 구현되기 때문이라고 한다.
1. Run-Length Encoding (RLE)
연속된 같은 데이터를 "개수+문자"로 바꿔서 공간을 절약하는 알고리즘이다.
원본 데이터: AAAAABBBCCCCNNNN (16글자)
압축 후: 5A3B4C4N (8글자)
2. Huffman coding (허프만 코딩)
각 문자의 출현 빈도수에 따라 이진 코드를 할당하며 빈도수가 많을수록 짧은 이진 코드를 할당한다.
조금 복잡한 방식이라 그림을 그려보면 다음과 같은 과정으로 이진 코드를 할당하게 된다.
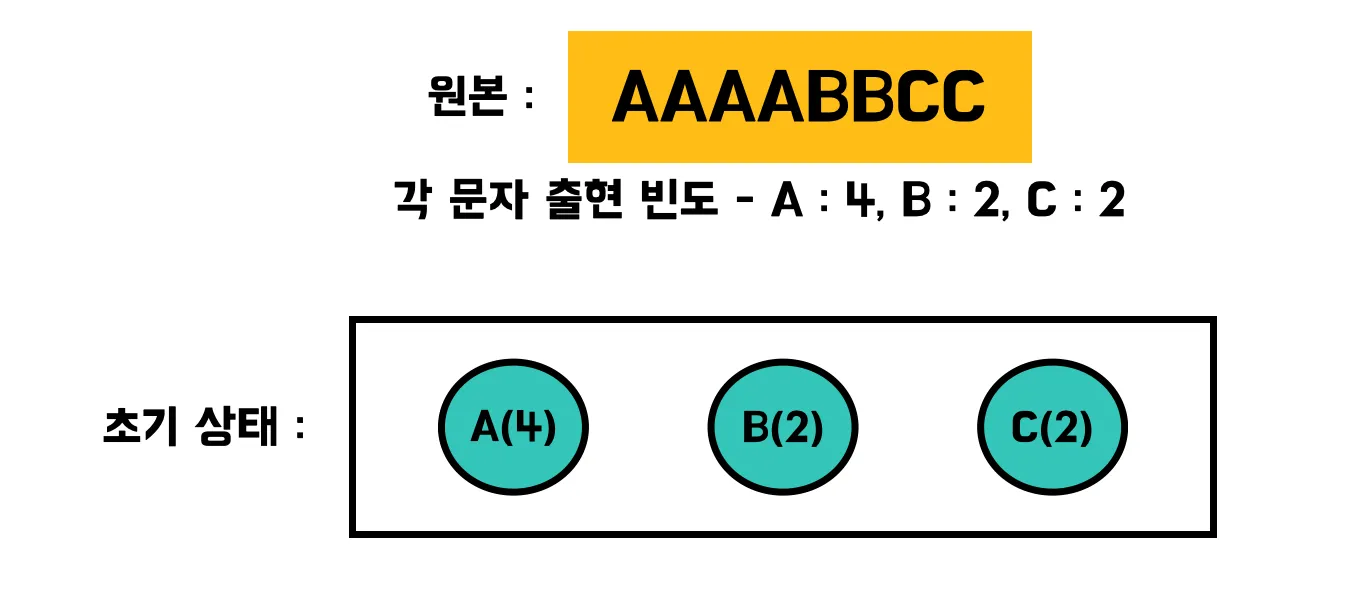


Lempel-Ziv
반복되는 구조나 패턴을 찾아서 "복사-붙여넣기" 방식으로 압축하는 알고리즘이다.
원본: "오늘 날씨가 좋다. 오늘 날씨가"
압축 후: "오늘 날씨가 좋다. (앞의 7글자 복사)"
무손실 압축은 압축 포맷에 따라 압축 알고리즘을 조합해 색상의 손실 없이 압축이 가능하다고 한다.
무손실 압축 특징
- 원본 데이터를 완전히 복원 가능
- 압축 해제 시 원본과 100% 동일한 데이터 복구
- 중복성과 패턴을 이용한 압축
- 상대적으로 낮은 압축률
Java를 사용한 이미지 압축
이제 이미지 압축을 적용해 보자.
Image 클래스의 데이터를 조작하기 위해선 BufferedImage 클래스를 활용해야 한다.
Image 클래스는 읽기 전용으로 이미지의 픽셀 데이터를 조작할 수 없기 때문이다.
압축을 적용한 코드는 다음과 같다.
@Slf4j
public record CompressedImage(byte[] data, int width, int height) {
public Image toImage() {
try {
ByteArrayInputStream bais = new ByteArrayInputStream(data);
return new Image(bais);
} catch (Exception exception) {
log.error("Failed to convert compressed data to Image", exception);
throw new RuntimeException("Failed to convert compressed data to Image");
}
}
}
@Slf4j
@Component
public class PDFImageCacheManager {
private static final int MAX_CACHE_SIZE = 20;
private static final String FORMAT_TYPE = "png";
private final Map<Integer, CompressedImage> pageCache = new LinkedHashMap<>(MAX_CACHE_SIZE, 0.75f, true) {
@Override
protected boolean removeEldestEntry(Map.Entry<Integer, CompressedImage> eldest) {
return size() > MAX_CACHE_SIZE;
}
};
public Image getCacheImageFrom(int pageIndex) {
CompressedImage compressed = pageCache.get(pageIndex);
if (compressed == null) {
return null;
}
return compressed.toImage();
}
public void addCache(int pageIndex, Image image) {
try {
BufferedImage buffered = SwingFXUtils.fromFXImage(image, null);
byte[] compressedData = compress(buffered);
CompressedImage compressedImage = new CompressedImage(
compressedData,
(int) image.getWidth(),
(int) image.getHeight()
);
pageCache.put(pageIndex, compressedImage);
} catch (IOException e) {
log.error("Failed to compress and cache image as PNG for page {}", pageIndex, e);
}
}
private byte[] compress(BufferedImage image) throws IOException {
ByteArrayOutputStream baos = new ByteArrayOutputStream(); // 압축된 이미지 데이터를 메모리에 임시 저장하기 위함
ImageIO.write(image, FORMAT_TYPE, baos); // BufferedImage → 압축 형식으로 이미지 변환
return baos.toByteArray(); // 압축된 이미지의 바이트 배열 반환
}
... 생략
}
동작 과정을 순서데로 보면 다음과 같다.
- JavaFX Image → BufferedImage 변환
- ByteArrayOutputStream 객체 생성
- BufferedImage를 지정된 형식(PNG)으로 압축하여 압축된 이미지 데이터를 ByteArrayOutputStream에 임시 저장
- 압축된 이미지의 바이트 배열 반환
- 캐시에 저장
압축 전 후 비교
압축전 평균 이미지 크기는 2MB였다.
-- PNG 압축후 - 화질 저하 없음
PDFImageCacheManager : page 2 | size 639 x 833 | memory usage: 0.02MB
-- JPG 압축후 (quality 수치별 비교)
// quality - 0.8 : 화질 저하 없음
PDFImageCacheManager : page 2 | size 639 x 833 | memory usage: 0.03MB
// quality - 0.5 : 화질 저하 미미
PDFImageCacheManager : page 2 | size 639 x 833 | memory usage: 0.02MB
// quality - 0.1 : 화질 저하 상당함
PDFImageCacheManager : page 2 | size 639 x 833 | memory usage: 0.01MB보면 무손실 압축으로도 충분히 효율적으로 용량을 줄일 수 있었고 화질 저하도 없었다.
테스트로 이뤄진 PDF 책 페이지 이미지상 아무래도 텍스트들은 명확한 경계들이 구분되어 있고, 색감이 복잡하지 않고 단순하고 반복되는 색감들로 이뤄졌기 때문에 손실 압축의 효과는 크게 못본 것으로 예상된다.
따라서 무손실 압축의 중복 제거로 손실 압축과 큰 차이 없이 충분히 많은 용량을 줄일 수 있었던 PNG 압축을 선택하였다.
처음으로 이미지 압축을 알아보고 적용해봤는데
손실 압축, 무손실 압축의 원리를 잘 이해하면 이미지의 활용 용도, 패턴에 따라 어떤 압축이 최고의 효율을 낼 수 있을지 적절하게 선택할 수 있을 거라 생각된다.
'◼ JAVA' 카테고리의 다른 글
| [Java] JVM 메모리 구조 파헤쳐 보기 (Static, Stack, Heap) (1) | 2024.04.14 |
|---|---|
| [Java] JVM이란? 구조와 특징에 대해 알아보자. (1) | 2024.04.14 |
| [엘레강스 오브젝트] "생성자에 코드를 넣지 마세요" 내용에 대한 생각 (1) | 2024.04.11 |
| [Java] 개행 문자 사용시 주의점 (OS별 개행문자 통일하는 법) (1) | 2024.04.11 |
| [Java] 함수 파라미터에 final 키워드를 꼭 붙여야 할까? (0) | 2024.04.11 |