


정규식이란 텍스트 데이터 중에서 원하는 조건(Pattern)과 일치하는 문자열을 찾아 내기 위해 사용하는 것으로,
정규식을 이용하면 많은 양의 텍스트 파일 중에서 원하는 데이터를 손쉽게 뽑아낼 수도 있고, 입력된 데이터가 형식에 맞는지 체크할 수 도 있습니다.
java.util.regex패키지
public static void main(String[] args) {
String[] data = {"bat", "baby", "bonus",
"cA", "ca", "co", "c.", "c0", "car", "combat", "count",
"date", "disc"};
Pattern p = Pattern.compile("c[a-z]*"); // c로 시작하는 소문자영단어
for (int i = 0; i < data.length; i++) {
Matcher m = p.matcher(data[i]);
if (m.matches()) {
System.out.print(data[i] + ",");
}
}
}
Pattern 클래스
Pattern은 정규식을 정의하는데 사용합니다.
String[] data = {"bac", "Ca", "co", "c.", "c0", "car", "combat", "count", "date", "disc"};
Pattern p = Pattern.compile("c[a-z]*"); // c로 시작하는 소문자영단어
Pattern클래스에는 아래와 같은 메서드들이 포함되어 있습니다.
| 메서드 | 반환 타입 | 설 명 |
| compile(String regex) | Pattern | 주어진 정규식을 갖는 패턴을 생성 |
| pattern() | String | 컴파일된 정규 표현식을 반환 |
| matcher(CharSequence input) | Matcher | 패턴에 매칭할 문자열을 입력해 Matcher를 생성 |
| matches(String regex, CharSequence input) | boolean | 정규식과 문자열이 일치하는지 확인 |
| split(CharSequence input) split(CharSequence input, int limit) |
String[] | 패턴이 일치하는 항목을 중심으로 input을 분할 limit - 1의 횟수만큼 패턴 일치를 시켜 문자열을 자름(문자열이 limit개 생성) 만약 0이하라면 최대한 많이 적용 |
Matcher 클래스
Matcher는 정의한 정규식(Pattern)을 가지고 데이터와 비교하는 역할을 합니다.
public static void main(String[] args) {
String[] data = {"bac", "Ca", "co", "c.", "c0", "car", "combat", "count", "date", "disc"};
Pattern p = Pattern.compile("c[a-z]*"); // c로 시작하는 소문자영단어
for (int i = 0; i < data.length; i++) {
Matcher m = p.matcher(data[i]);
if (m.matches()) {
System.out.print(data[i] + ",");
}
}
}Matcher클래스에는 아래와 같은 메서드들이 포함되어 있습니다.
| 메서드 | 반환 타입 | 설 명 |
| pattern() | Pattern | matcher가 해석한 패턴을 반환 |
| usePattern(Pattern newPattern) | Matcher | matcher가 사용할 Pattern을 변경 |
| reset(CharSequence input) | Matcher | matcher가 분석할 문자열을 변경 |
| start() | int | 매칭하는 문자열의 시작 인덱스를 반환 |
| start(int group) | int | 매칭 문자열 중 group번째 문자열의 시작 인덱스를 반환 0은 그룹의 전체 패턴을 의미 start(0) = start() |
| start(String name) | int | 매칭 문자열 중 해당 name을 지정한 그룹의 시작 인덱스를 반환 |
| end() | int | 일치하는 문자열의 마지막 문자열 이후 인덱스를 반환 |
| end(int group) | int | 매칭 문자열 중 group번째 그룹의 마지막 문자열 이후(+1) 인덱스를 반환 0은 그룹의 전체 패턴을 의미 end(0) = end() |
| end(String name) | int | 매칭 문자열 중 해당 name을 지정한 그룹의 마지막 문자열 이후(+1) 인덱스를 반환 |
| group() | String | 매치와 일치하는 문자열을 반환 |
| group(int group) | String | 매칭되는 문자열 중 group번째 그룹의 문자열 반환 0은 그룹의 전체 패턴을 의미 group(0) = group() |
| group(String name) | String | 매칭되는 문자열 중 해당 name을 지정한 그룹의 문자열 반환 |
| groupCount() | int | 패턴 내에 그룹핑한 개수를 반환(패턴에 있는 괄호 개수) |
| matches() | boolean | 패턴에 전체 문자열이 일치한 경우 true를 반환 |
| find() | boolean | 패턴이 일치하는 다음 문자열을 찾는다 다음 문자열이 있다면 true |
| find(int start) | boolean | start 인덱스 이후부터 패턴에 일치하는 문자열을 찾는다 |
| replaceAll(String replacement) | String | 패턴과 일치하는 모든 문자열을 지정된 replacement로 변경 |
정규 표현식 문법
| 정규 표현식 | 설명 | 예시 |
| ^ | 문자열의 시작을 의미. [] 괄호 안에 있다면 일치하지 않는 부정의 의미로로 쓰인다 |
^a : a로 시작하는 단어 [^a] : a가 아닌 철자인 문자 1개 |
| $ | $앞의 문자열로 문자가 끝나는지를 의미. | a$ : a로 끝나는 단어 |
| . | 임의의 문자 1개를 의미. (단 \은 넣을 수 없음) | |
| * | 앞 문자가 없을 수도 무한정 많을 수도 있다. | a1* : 1이 있을수도 없을수도 있다 -> a (o), a1(o), a2(o) |
| + | 앞 문자가 하나 이상 | a1+ : 1이 1개 이상있다 -> a (x), a1(o), a11(o) |
| ? | 앞 문자가 없거나 하나 있음 | a1? : 1이 하나 있을수도 없을수도 있다 -> a (o), a1(o), a2(o) |
| - | 사이의 문자 혹은 숫자를 의미 | [a-z] : 알파벳 소문자 a부터 z까지 [a-z0-9] : 알파벳 소문자 전체,0~9 중 한 문자 |
| [ ] | 문자의 집합이나 범위를 나타내며 두 문자 사이는 - 기호로 범위를 나타냅니다. [] 내에서 ^ 가 선행하여 존재하면 not을 나타냅니다. |
[ab][cd] : a,b중 한 문자와 c,d중 한 문자 -> ac ad bc bd |
| { } | 횟수 또는 범위를 나타냅니다. (개수) | a{3}b : a가 3번 온 후 b가 온다 -> aab(x), aaab(o), aaaab(o) |
| {n} | 정확히 n개 | a{3} : a가 3개 있다 -> aa(x), aaa(o) |
| {n, m} | n개 이상 m개 이하 | a{3,5} : a가 3개이상 5개이하 있다 -> aa(x), aaa(o), aaaa(o), aaaaa(o) |
| {n,} |
최소한 n개 | a{3,} : a가 3개 이상 있다 -> aa(x), aaa(o) |
| ( ) | 소괄호 안의 문자를 하나의 문자로 인식 (그룹) | 01 (0|1) : 01뒤에 0 또는 1이 들어간다 -> 010(o), 011(o), 012(x) |
| | | 패턴 안에서 or 연산을 수행할 때 사용 | [a|b] : a 혹은 b |
| \ | 정규 표현식 역슬래시(\)는 확장문자 역슬래시 다음에 일반 문자가 오면 특수문자로 취급하고 역슬래시 다음에 특수문자가 오면 그 문자 자체를 의미 |
알파벳이나 숫자를 나타내는 \w 같은 경우 Java에서 \ 자체는 특수문자로 취급하기 때문에, 알파벳이나 숫자를 판별하는 정규식 기호는 다음과 같이 작성을 해야합니다. \\w |
| \b | 공백, 탭, ",", "/" 등을 의미 | apple\b : apple뒤에 공백 탭등이 있다 -> apple juice (o), apple.com (x) |
| \B | \b의 부정 공백 탭등이 아닌 문자인 경우 매치 |
apple\b -> apple.com (o) |
| \s | 공백, 탭 | |
| \S | \s 부정 공백, 탭이 아닌 나머지 문자 |
|
| \w | 알파벳이나 숫자 [a-zA-Z_0-9]와 동일 |
|
| \W | \w의 부정 알파벳이나 숫자를 제외한 문자 = [^a-zA-Z_0-9] |
|
| \d | 0~9 사이의 숫자 숫자 [0-9]와 동일 |
|
| \D | \d의 부정 숫자를 제외한 모든 문자 = [^0-9] |
|
| (?i) | 앞 부분에 (?!)라는 옵션을 넣어주게 되면 대소문자는 구분하지 않습니다. |
자주 사용하는 패턴의 정규 표현식
| 정규 표현식 | 의미 |
| ^[0-9]*$ | 모든 값이 숫자 |
| [1-9]+ | 1~9의 범위의 수 |
| ^[a-zA-Z]*$ | 알파벳 |
| ^[가-힣]*$ | 한글 |
| ^[a-zA-Z0-9] | 알파벳이나 숫자 |
| ^[a-zA-Z0-9]+@[a-zA-Z0-9]+\\.[a-z]+$ | 이메일(Email) |
| \w+@\w+\.\w+(\\.\\w+)? | 이메일(Email) |
| ^01(?:0|1|[6-9])-(?:\\d{3}|\\d{4})-\\d{4}$ | 휴대폰 번호 |
| \d{6} \- [1-4]\d{6} |
주민등록 번호 |
| ^\d{3}-\d{2}$ | 우편번호 |
정규식 예제
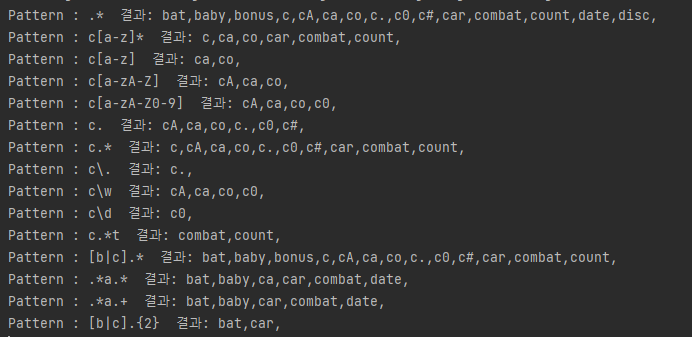
import java.util.regex.*;
class RegularEx2 {
public static void main(String[] args) {
String[] data = {"bat", "baby", "bonus", "c", "cA",
"ca", "co", "c.", "c0", "c#",
"car", "combat", "count", "date", "disc"
};
String[] pattern = {".*", "c[a-z]*", "c[a-z]", "c[a-zA-Z]",
"c[a-zA-Z0-9]", "c.", "c.*", "c\\.", "c\\w",
"c\\d", "c.*t", "[b|c].*", ".*a.*", ".*a.+",
"[b|c].{2}"
};
for (int x = 0; x < pattern.length; x++) {
Pattern p = Pattern.compile(pattern[x]);
System.out.print("Pattern : " + pattern[x] + " 결과: ");
for (int i = 0; i < data.length; i++) {
Matcher m = p.matcher(data[i]);
if (m.matches()) {
System.out.print(data[i] + ",");
}
}
System.out.println();
}
}
}
참고자료
자바의 정석3
https://hbase.tistory.com/160
https://girawhale.tistory.com/77
반응형
'◼ JAVA' 카테고리의 다른 글
| [Java/자바] map - getOrDefault의 활용 (0) | 2022.12.05 |
|---|---|
| [Java/자바] List와 String(문자열, 배열)을 서로 변환하는 법 (0) | 2022.12.04 |
| [Java/자바] 람다식(Lambda)이란? 그리고 사용법 (4) | 2022.11.27 |
| [Java/자바] Enum(열거형)이란? (0) | 2022.11.25 |
| [우아한테크코스 백엔드 5기] 프리코스 4주차 후기 (다리 건너기) (0) | 2022.11.23 |